进一步扩展之前的答案...
从一个通用编译器的视角来看,不考虑虚拟机特定的优化:
首先,我们进行词法分析阶段,其中我们对代码进行标记化。
例如,可以生成以下标记:
[]: ARRAY_INIT
[1]: ARRAY_INIT (NUMBER)
[1, foo]: ARRAY_INIT (NUMBER, IDENTIFIER)
new Array: NEW, IDENTIFIER
new Array(): NEW, IDENTIFIER, CALL
new Array(5): NEW, IDENTIFIER, CALL (NUMBER)
new Array(5,4): NEW, IDENTIFIER, CALL (NUMBER, NUMBER)
new Array(5, foo): NEW, IDENTIFIER, CALL (NUMBER, IDENTIFIER)
希望这能为你提供足够的可视化,以便你可以了解需要处理多少更多(或更少)的内容。
基于上述标记,我们知道ARRAY_INIT将始终产生一个数组。因此,我们只需创建一个数组并填充它即可。就歧义而言,词法分析阶段已经将ARRAY_INIT与对象属性访问器(例如
obj [foo])或字符串/正则表达式字面量内部的括号(例如"foo [] bar"或/ [] /)区分开来这很小,但我们还有更多的标记与
new Array一起使用。此外,尚不完全清楚我们是否只想创建一个数组。我们看到“new”标记,但是“new”的是什么?然后我们看到IDENTIFIER标记,表示我们想要一个新的“Array”,但JavaScript VM通常不区分IDENTIFIER标记和用于“本机全局对象”的标记。因此...每次遇到IDENTIFIER标记时,我们必须查找作用域链。Javascript VM为每个执行上下文包含一个“Activation object”,其中可能包含“arguments”对象、本地定义变量等。如果在Activation对象中找不到它,则开始查找作用域链,直到达到全局范围。如果没有找到,则抛出
ReferenceError。找到变量声明后,我们调用构造函数。
new Array是一个隐式函数调用,并且经验法则是执行期间函数调用更慢(这就是为什么静态C/C++编译器允许“函数内联”的原因 - JS JIT引擎(如SpiderMonkey)必须即时完成这一点的原因)Array构造函数被重载。Array构造函数作为本机代码实现,因此它提供了一些性能增强,但仍需要检查参数长度并根据情况采取行动。此外,在仅提供一个参数的情况下,我们还需要进一步检查参数的类型。new Array(“foo”)会产生["foo"],而new Array(1)会产生[undefined]
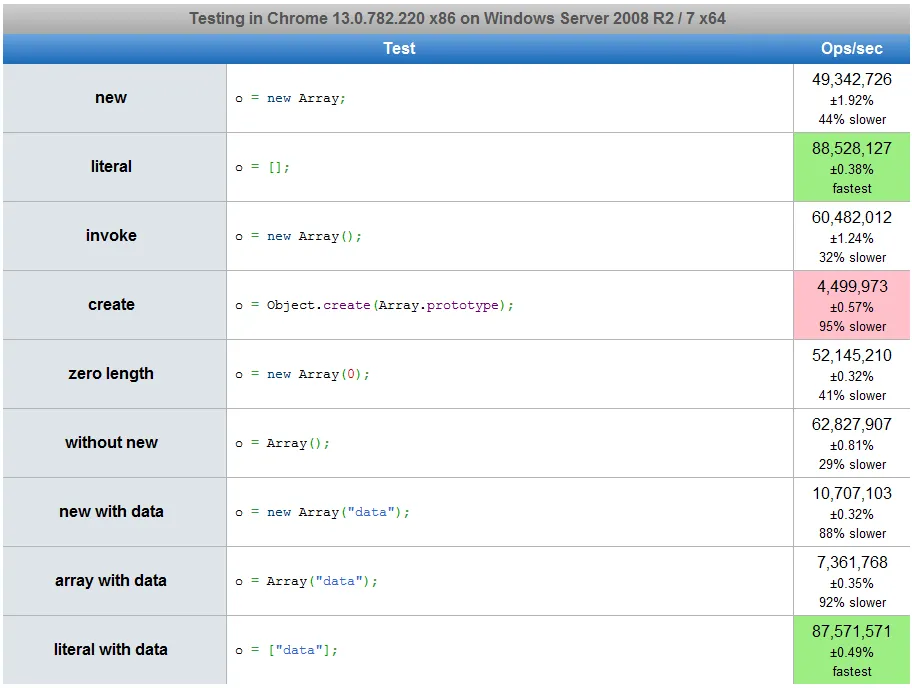
所以简化所有这些:使用数组文字,VM知道我们想要一个数组;对于new Array ,VM需要使用额外的CPU周期来确定new Array 实际上做了什么。
2
可能的一个原因是new Array在Array上需要进行名称查找(您可以在作用域中使用该名称的变量),而[]则不需要。
4
Array 接受一个名为 len 的参数和多个参数。而 [] 只接受多个参数。此外,Firefox 测试显示几乎没有区别。 - Raynosvar Array = window.Array 可以提高 new Array 测试的性能。 - user113716"new Array(%ARR_LENGTH%)" - 快100%!
"[]" - 慢160-170%。
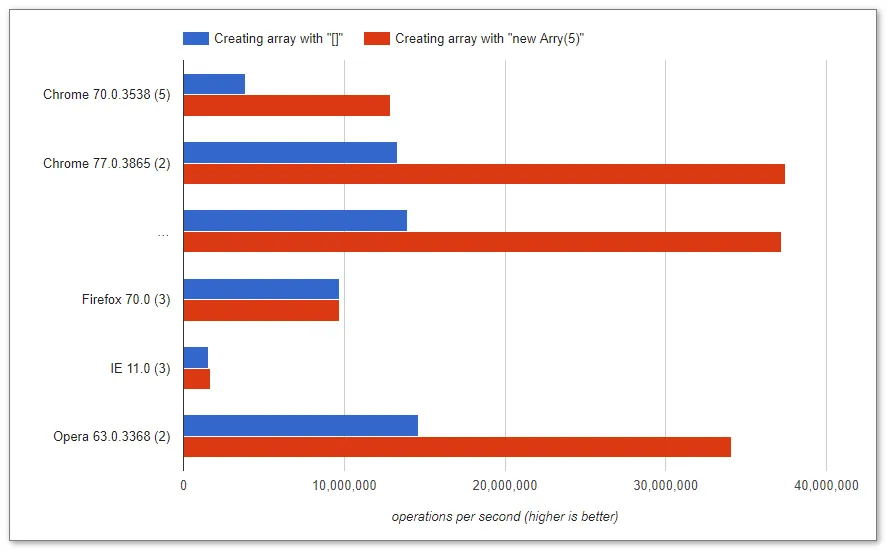
测试可以在这里找到 - https://jsperf.com/small-arr-init-with-known-length-brackets-vs-new-array/2
注意:此结果在 Google Chrome v.70+ 上测试;在 Firefox v.70 和 IE 中,两种变体几乎相等。
好问题。第一个例子被称为数组字面量,它是许多开发人员首选的创建数组的方式。可能是由于检查new Array()调用的参数然后创建对象导致性能差异,而字面量直接创建数组。
相对较小的性能差异支持这一点。顺便说一下,您可以使用Object和对象字面量{}进行相同的测试。
这样做有些意义。
对象字面量使我们能够编写支持许多功能的代码,同时仍然使我们的代码实现者相对简单。无需直接调用构造函数或维护传递给函数的参数的正确顺序等。
原文链接
- 相关问题
- 4 std::tuple比std::array更快吗?
- 11 在Ruby中,`arr << x`比`arr += [x]`更快。
- 796 为什么[]比list()更快?
- 5 jQuery $.each(arr, foo)与$(arr).each(foo)的区别
- 8 使用 var arr=[]; 比使用 var arr=new Array(); 更好么?
- 3 在 JavaScript 中重置数组时,arr.length = 0 比 arr = [] 更好吗?
- 3 为什么使用 new Function(code) 比直接执行同样的代码更快?
- 4 JavaScript 性能优化(typeof arr[i] === "undefined" || num < arr[i])
- 77 为什么array.push有时比array[n] = value更快?
- 6 为什么遍历`std::vector`比遍历`std::array`更快?
[]在源代码上等同于new Array(),而不是从表达式返回的对象。 - Raynos