考虑这个mcve:
import math
import sys
import textwrap
import time
from pathlib import Path
from collections import defaultdict
from PyQt5.Qsci import QsciLexerCustom, QsciScintilla
from PyQt5.Qt import *
from pygments import lexers, styles, highlight, formatters
from pygments.lexer import Error, RegexLexer, Text, _TokenType
from pygments.style import Style
EXTRA_STYLES = {
"monokai": {
"background": "#272822",
"caret": "#F8F8F0",
"foreground": "#F8F8F2",
"invisibles": "#F8F8F259",
"lineHighlight": "#3E3D32",
"selection": "#49483E",
"findHighlight": "#FFE792",
"findHighlightForeground": "#000000",
"selectionBorder": "#222218",
"activeGuide": "#9D550FB0",
"misspelling": "#F92672",
"bracketsForeground": "#F8F8F2A5",
"bracketsOptions": "underline",
"bracketContentsForeground": "#F8F8F2A5",
"bracketContentsOptions": "underline",
"tagsOptions": "stippled_underline",
}
}
def convert_size(size_bytes):
if size_bytes == 0:
return "0B"
size_name = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
i = int(math.floor(math.log(size_bytes, 1024)))
p = math.pow(1024, i)
s = round(size_bytes / p, 2)
return f"{s} {size_name[i]}"
class ViewLexer(QsciLexerCustom):
def __init__(self, lexer_name, style_name):
super().__init__()
# Lexer + Style
self.pyg_style = styles.get_style_by_name(style_name)
self.pyg_lexer = lexers.get_lexer_by_name(lexer_name, stripnl=False)
self.cache = {
0: ('root',)
}
self.extra_style = EXTRA_STYLES[style_name]
# Generate QScintilla styles
self.font = QFont("Consolas", 8, weight=QFont.Bold)
self.token_styles = {}
index = 0
for k, v in self.pyg_style:
self.token_styles[k] = index
if v.get("color", None):
self.setColor(QColor(f"#{v['color']}"), index)
if v.get("bgcolor", None):
self.setPaper(QColor(f"#{v['bgcolor']}"), index)
self.setFont(self.font, index)
index += 1
def defaultPaper(self, style):
return QColor(self.extra_style["background"])
def language(self):
return self.pyg_lexer.name
def get_tokens_unprocessed(self, text, stack=('root',)):
"""
Split ``text`` into (tokentype, text) pairs.
``stack`` is the inital stack (default: ``['root']``)
"""
lexer = self.pyg_lexer
pos = 0
tokendefs = lexer._tokens
statestack = list(stack)
statetokens = tokendefs[statestack[-1]]
while 1:
for rexmatch, action, new_state in statetokens:
m = rexmatch(text, pos)
if m:
if action is not None:
if type(action) is _TokenType:
yield pos, action, m.group()
else:
for item in action(lexer, m):
yield item
pos = m.end()
if new_state is not None:
# state transition
if isinstance(new_state, tuple):
for state in new_state:
if state == '#pop':
statestack.pop()
elif state == '#push':
statestack.append(statestack[-1])
else:
statestack.append(state)
elif isinstance(new_state, int):
# pop
del statestack[new_state:]
elif new_state == '#push':
statestack.append(statestack[-1])
else:
assert False, "wrong state def: %r" % new_state
statetokens = tokendefs[statestack[-1]]
break
else:
# We are here only if all state tokens have been considered
# and there was not a match on any of them.
try:
if text[pos] == '\n':
# at EOL, reset state to "root"
statestack = ['root']
statetokens = tokendefs['root']
yield pos, Text, u'\n'
pos += 1
continue
yield pos, Error, text[pos]
pos += 1
except IndexError:
break
def highlight_slow(self, start, end):
style = self.pyg_style
view = self.editor()
code = view.text()[start:]
tokensource = self.get_tokens_unprocessed(code)
self.startStyling(start)
for _, ttype, value in tokensource:
self.setStyling(len(value), self.token_styles[ttype])
def styleText(self, start, end):
view = self.editor()
t_start = time.time()
self.highlight_slow(start, end)
t_elapsed = time.time() - t_start
len_text = len(view.text())
text_size = convert_size(len_text)
view.setWindowTitle(f"Text size: {len_text} - {text_size} Elapsed: {t_elapsed}s")
def description(self, style_nr):
return str(style_nr)
class View(QsciScintilla):
def __init__(self, lexer_name, style_name):
super().__init__()
view = self
# -------- Lexer --------
self.setEolMode(QsciScintilla.EolUnix)
self.lexer = ViewLexer(lexer_name, style_name)
self.setLexer(self.lexer)
# -------- Shortcuts --------
self.text_size = 1
self.s1 = QShortcut(f"ctrl+1", view, self.reduce_text_size)
self.s2 = QShortcut(f"ctrl+2", view, self.increase_text_size)
# self.gen_text()
# # -------- Multiselection --------
self.SendScintilla(view.SCI_SETMULTIPLESELECTION, True)
self.SendScintilla(view.SCI_SETMULTIPASTE, 1)
self.SendScintilla(view.SCI_SETADDITIONALSELECTIONTYPING, True)
# -------- Extra settings --------
self.set_extra_settings(EXTRA_STYLES[style_name])
def get_line_separator(self):
m = self.eolMode()
if m == QsciScintilla.EolWindows:
eol = '\r\n'
elif m == QsciScintilla.EolUnix:
eol = '\n'
elif m == QsciScintilla.EolMac:
eol = '\r'
else:
eol = ''
return eol
def set_extra_settings(self, dct):
self.setIndentationGuidesBackgroundColor(QColor(0, 0, 255, 0))
self.setIndentationGuidesForegroundColor(QColor(0, 255, 0, 0))
if "caret" in dct:
self.setCaretForegroundColor(QColor(dct["caret"]))
if "line_highlight" in dct:
self.setCaretLineBackgroundColor(QColor(dct["line_highlight"]))
if "brackets_background" in dct:
self.setMatchedBraceBackgroundColor(QColor(dct["brackets_background"]))
if "brackets_foreground" in dct:
self.setMatchedBraceForegroundColor(QColor(dct["brackets_foreground"]))
if "selection" in dct:
self.setSelectionBackgroundColor(QColor(dct["selection"]))
if "background" in dct:
c = QColor(dct["background"])
self.resetFoldMarginColors()
self.setFoldMarginColors(c, c)
def increase_text_size(self):
self.text_size *= 2
self.gen_text()
def reduce_text_size(self):
if self.text_size == 1:
return
self.text_size //= 2
self.gen_text()
def gen_text(self):
content = Path(__file__).read_text()
while len(content) < self.text_size:
content *= 2
self.setText(content[:self.text_size])
if __name__ == '__main__':
app = QApplication(sys.argv)
view = View("python", "monokai")
view.setText(textwrap.dedent("""\
'''
Ctrl+1 = You'll decrease the size of existing text
Ctrl+2 = You'll increase the size of existing text
Warning: Check the window title to see how long it takes rehighlighting
'''
"""))
view.resize(800, 600)
view.show()
app.exec_()
运行此程序需要安装以下内容:
QScintilla==2.10.8
Pygments==2.3.1
PyQt5==5.12
我正在尝试找出如何在QScintilla小部件上使用Pygments,目前我需要解决的主要问题是处理非微小文档时的性能。
我希望编辑器在处理大型文档(>=100KB)时变得响应和可用,但我不太清楚我应该采取什么方法。为了测试性能,您可以使用Ctrl+1或Ctrl+2,小部件文本将相应地减少/增加。
当我说“响应”时,我指的是可见屏幕的高亮计算不应超过[1-2]帧/高亮 <=> [17-34]ms/高亮(假设为60fps),因此在输入时您不会感到任何减速。
注意:正如您在上面的mcve中看到的,我已包含了Pygments tokenizer,因此您可以玩弄它…感觉上,为了实现“实时高亮”,我需要以某种聪明的方式使用备忘录化/缓存,但我很难弄清楚需要缓存的数据以及最佳缓存方式… :/
Demo:
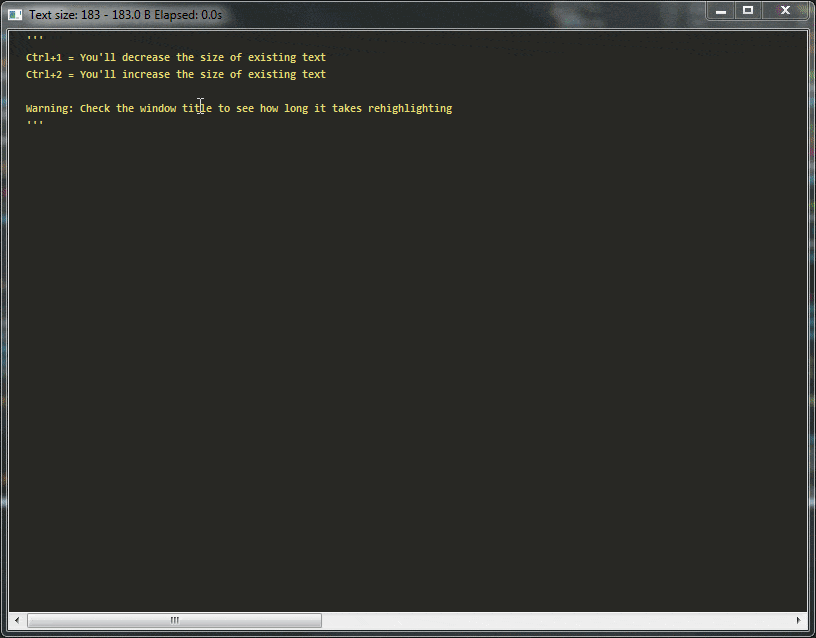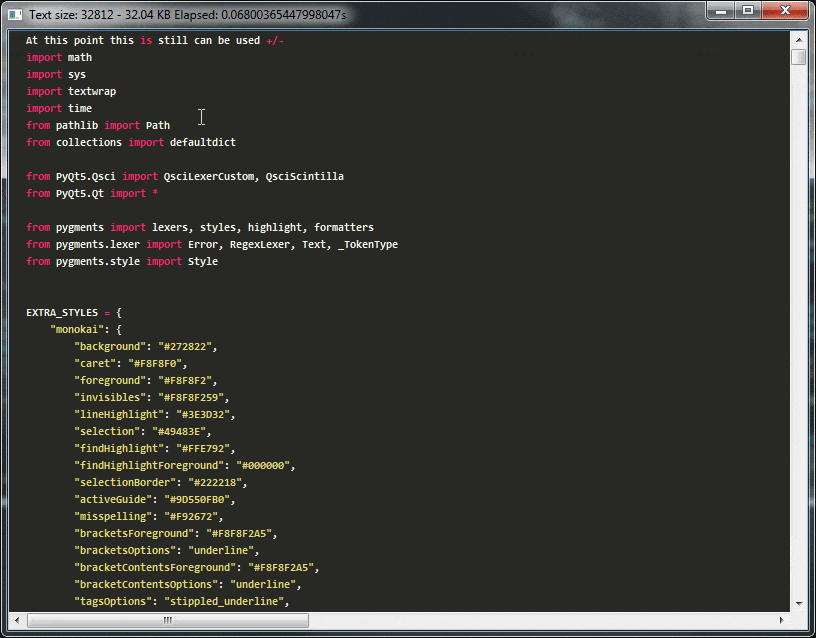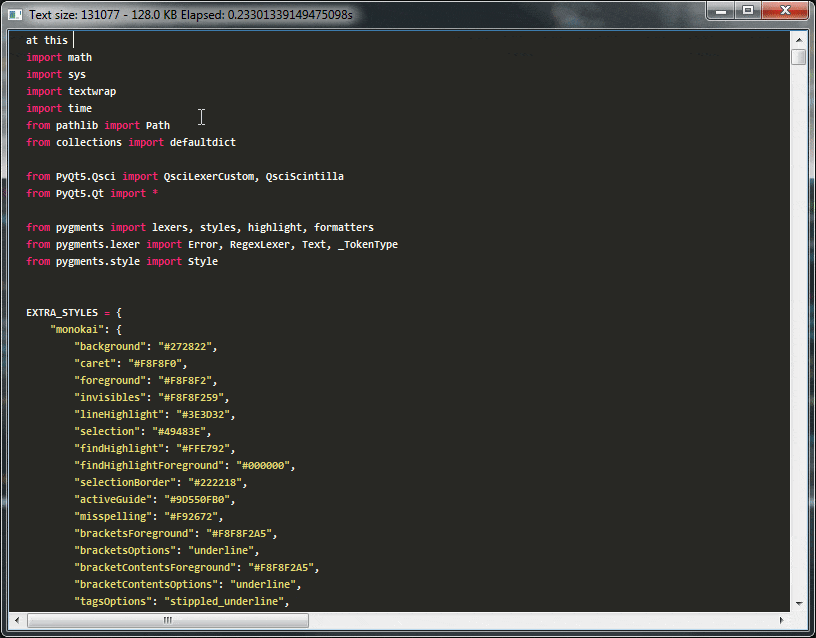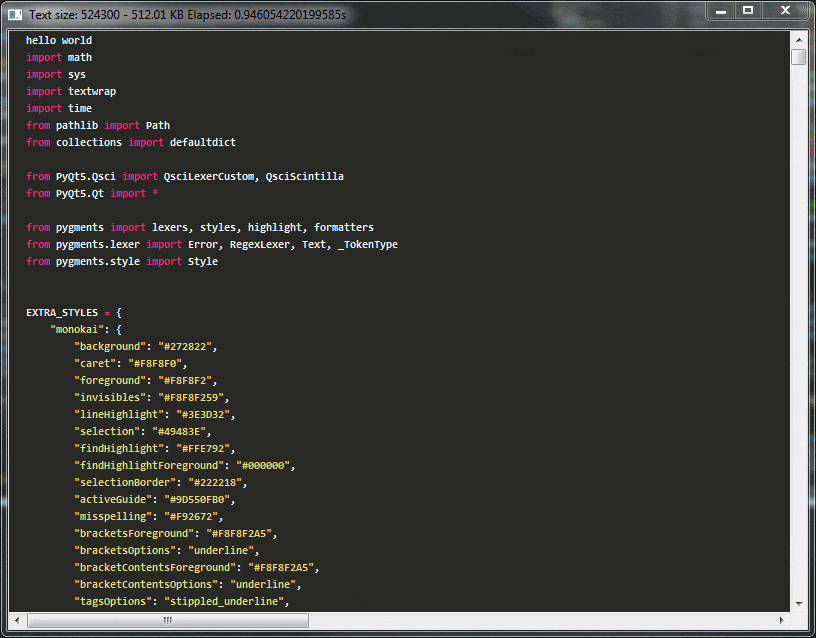
在上面的演示中,您可以看到使用这种天真高亮语法,编辑器很快将变得无法使用,在我的笔记本电脑上重新突出显示32kb文本块仍然具有交互帧速率,但超过此大小后,编辑器将完全无法使用。
注意事项:
- 最典型的情况是在没有选择的情况下在可见屏幕上进行打字/编码
- 可能会发生您正在编辑分布在整个文档中的多个选择,这意味着您不知道这些选择是否靠近可见屏幕。例如,在Sublime中,当您按
Alt+F3时,将选择鼠标下的所有实例 - 在上面的片段中,我使用了Python词法分析器,但算法不应该过于关注特定的词法分析器。毕竟,Pygments支持大约300个词法分析器
- 最糟糕的情况将发生在可见屏幕位于文件末尾并且其中一个选择恰好位于屏幕开头的情况下…如果需要重新突出显示整个文档,则需要找到另一种方法,即使这意味着“突出显示”在第一遍通行中不正确
- 最重要的是性能,但也要正确…也就是说,如果给足够的时间,整个文档应该变成正确的高亮
参考资料:
- https://qscintilla.com/styletext-the-highlighting-engine/
- http://pygments.org/docs/
- https://www.riverbankcomputing.com/static/Docs/QScintilla/annotated.html
下面的文档与此特定问题无关,但它们谈论了可能