我的情况:
我有一个元组列表。这些元组的第一项表示目录中文件夹的级别,第二项表示文件夹的名称。这些元组还按照它们与目录的关系进行排序。
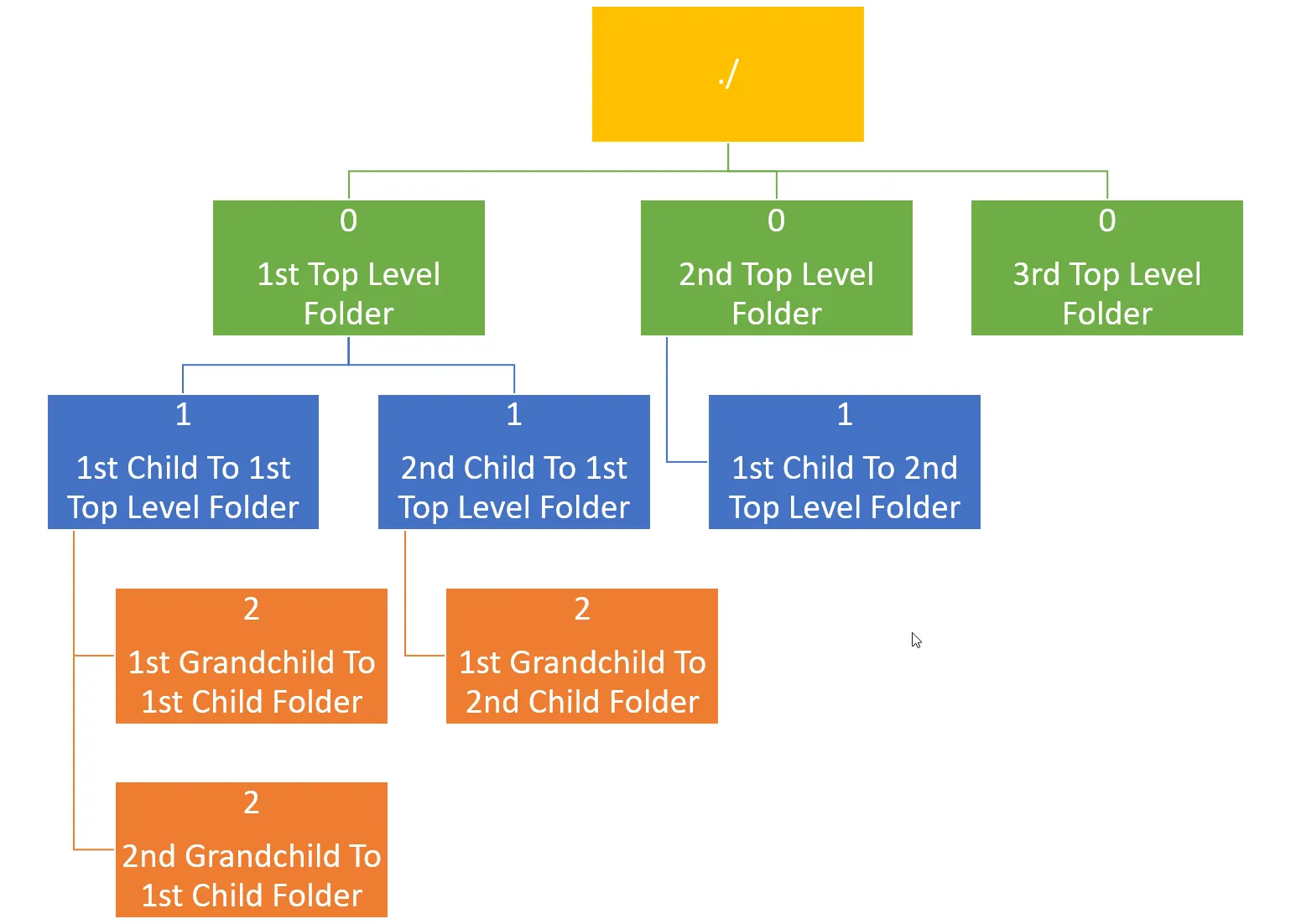
以下是列表的样子:
single_paths = [
[0, "1st Top Level Folder"],
[1, "1st Child To 1st Top Level Folder"],
[2, "1st Grandchild To 1st Child Folder"],
[2, "2nd Grandchild To 1st Child Folder"],
[1, "2nd Child To 1st Top Level Folder"],
[2, "1st Grandchild To 2nd Child Folder"],
[0, "2nd Top Level Folder"],
[1, "1st Child To 2nd Top Level Folder"],
[0, "3rd Top Level Folder"],
]
目录树的可视化表示:
我想要实现的目标: 得到一个所有可能路径的列表,其外观如下:
possible_paths = [
["1st Top Level Folder"],
["1st Top Level Folder", "1st Child To 1st Top Level Folder"],
["1st Top Level Folder", "1st Child To 1st Top Level Folder", "1st Grandchild To 1st Child Folder"],
["1st Top Level Folder", "1st Child To 1st Top Level Folder", "2nd Grandchild To 1st Child Folder"],
["1st Top Level Folder", "2nd Child To 1st Top Level Folder"],
["1st Top Level Folder", "2nd Child To 1st Top Level Folder", "1st Grandchild To 2nd Child Folder"],
["2nd Top Level Folder"],
["2nd Top Level Folder", "1st Child To 2nd Top Level Folder"],
["3rd Top Level Folder"],
]
您推荐使用哪种算法来实现这个功能?我已经花了3天的时间,但似乎无法得到正确的结果。非常感谢您提前的帮助。