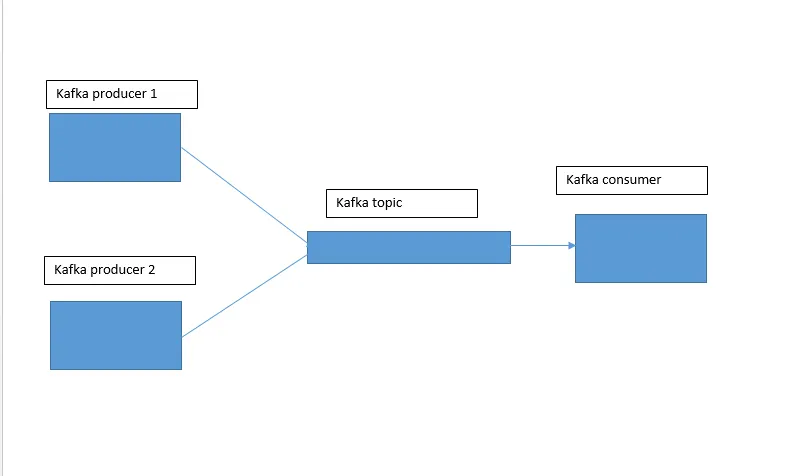
假设您实际上有多个不同的生产者编写相同的消息,我可以看到以下两个选项:1)将所有重复消息写入单个Kafka主题,然后使用类似于Kafka Streams(或任何其他流处理器,如Flink、Spark Streaming等)的工具来去重消息并将去重结果写入新主题。这是一个很好的Kafka Streams示例,使用状态存储:https://github.com/confluentinc/kafka-streams-examples/blob/4.0.0-post/src/test/java/io/confluent/examples/streams/EventDeduplicationLambdaIntegrationTest.java 2)确保重复的消息具有相同的消息键。之后,您需要启用日志压缩,Kafka将最终消除重复项。这种方法不太可靠,但如果适当调整压缩设置,它可能会给您想要的结果。
现在,Apache Kafka 支持精准一次性投递:https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/。