我想看一个例子:
- 何时使用合适
- 何时不合适
选用不同的数据库会影响以上示例吗?
我想看一个例子:
选用不同的数据库会影响以上示例吗?
这似乎是一个与代理键有关的问题,它们始终是自增长数字或GUID,因此是单列,而自然键通常需要多个信息才能真正唯一。如果您能够拥有一个只有一列的自然键,那么显然这个问题就无意义了。
有些人坚持只使用其中之一。花足够的时间在生产数据库上工作,你会发现没有独立于上下文的最佳实践。
其中一些答案使用SQL Server术语,但概念通常适用于所有DBMS产品:
聚集索引。当数据库仅需附加时,聚集索引始终表现最佳-否则,DB必须执行页面分裂。请注意,仅适用于键是顺序的,即自动增量序列或顺序GUID的情况。对于任意GUID,性能可能会更差。
关系。如果您的键是3、4、5列长,包括字符类型和其他非紧凑数据,则如果您必须在其他20个表中为此键创建外键关系,则会浪费巨大的空间,从而降低性能。
唯一性。有时您没有真正的自然键。也许您的表是某种日志,并且可能会在相同时间得到两个相同的事件。或者您的真实键类似于已物化的路径,只能在行插入后才能确定。无论哪种方式,您始终希望聚集索引和/或主键是唯一的,因此如果没有其他真正唯一的信息,您别无选择,只能使用代理键。
兼容性。 大多数人永远不必处理这个问题,但如果自然键包含像 hierarchyid 这样的内容,可能有些系统甚至无法读取它。在这种情况下,您必须为这些应用程序创建一个简单的自动生成的替代键。即使自然键中没有任何“奇怪”的数据,一些数据库库也很难处理多列主键,尽管这个问题正在迅速消失。
存储。 很多人从未处理过大型数据库,因此不需要考虑这个因素。但当一个表具有数十亿或数万亿行时,您将希望尽可能地减少该表中的绝对最小数据量。
复制。 是的,您可以使用 GUID 或顺序 GUID。 但 GUID 也有它们自己的权衡之处,如果您不能或不想出于某些原因使用 GUID,则多列自然键是复制方案的更好选择,因为它本质上是全局唯一的 - 也就是说,您不需要特殊算法使其唯一,它是根据定义唯一的。这使得分布式架构的推理非常容易。
插入/更新性能。 替代键并不是免费的。 如果您有一组唯一且频繁查询的列,因此需要在这些列上创建覆盖索引,则索引最终几乎与表一样大,这浪费空间并需要在做任何修改时更新第二个索引。如果您可以只在一个表上有一个索引(聚集索引),您应该这么做!
这就是我现在想到的。如果我突然想起其他内容,我会进行更新。
我认为通常情况下(至少从应用程序开发者的角度来看),将主键设置为自动生成的键并在多个列上创建唯一约束和索引更好。
我曾经遇到过几种令人头痛的情况,因为数据库管理员认为多列主键总是足够的,而未来的要求变化证明了这是不正确的。
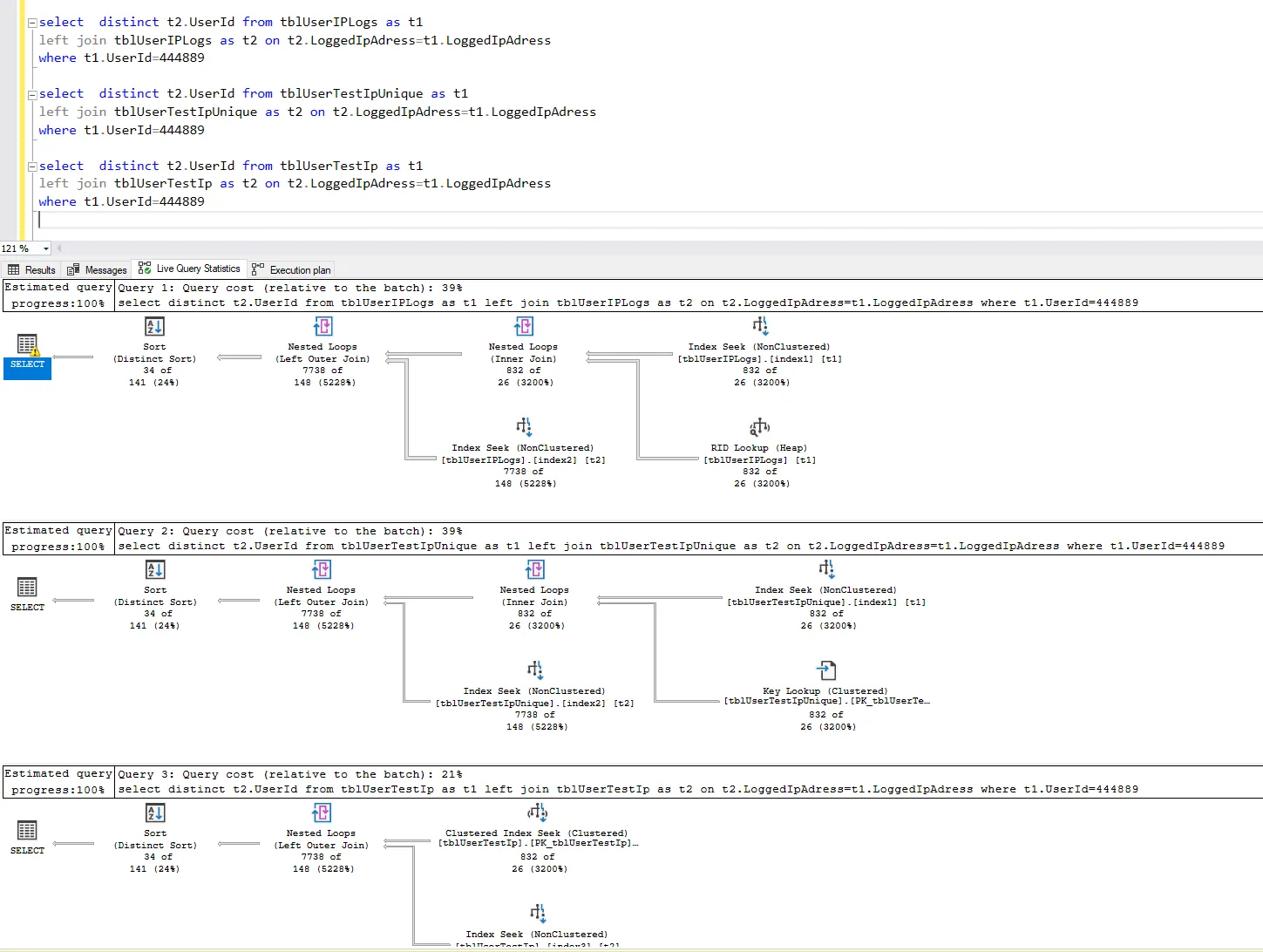
CREATE TABLE [dbo].[tblUserIPLogs](
[UserId] [int] NOT NULL,
[LoggedIpAdress] [varchar](15) NOT NULL,
[LoginDate] [datetime] NOT NULL
) ON [PRIMARY]
CREATE TABLE [dbo].[tblUserTestIp](
[UserId] [int] NOT NULL,
[LoggedIpAdress] [varchar](15) NOT NULL,
[LoginDate] [datetime] NOT NULL,
CONSTRAINT [PK_tblUserTestIp] PRIMARY KEY CLUSTERED
(
[UserId] ASC,
[LoggedIpAdress] ASC,
[LoginDate] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
CREATE TABLE [dbo].[tblUserTestIpUnique](
[Id] [int] IDENTITY(1,1) NOT NULL,
[UserId] [int] NOT NULL,
[LoggedIpAdress] [varchar](15) NOT NULL,
[LoginDate] [datetime] NOT NULL,
CONSTRAINT [PK_tblUserTestIpUnique] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [index1] ON [dbo].[tblUserIPLogs]
(
[UserId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
SET ANSI_PADDING ON
GO
CREATE NONCLUSTERED INDEX [index2] ON [dbo].[tblUserIPLogs]
(
[LoggedIpAdress] ASC
)
INCLUDE([UserId]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
SET ANSI_PADDING ON
GO
CREATE NONCLUSTERED INDEX [index3] ON [dbo].[tblUserTestIp]
(
[LoggedIpAdress] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [index1] ON [dbo].[tblUserTestIpUnique]
(
[UserId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
SET ANSI_PADDING ON
GO
CREATE NONCLUSTERED INDEX [index2] ON [dbo].[tblUserTestIpUnique]
(
[LoggedIpAdress] ASC
)
INCLUDE([UserId]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
ALTER TABLE [dbo].[tblUserIPLogs] ADD CONSTRAINT [DF_tblUserIPLogs_LoggedIpAdress] DEFAULT ('null') FOR [LoggedIpAdress]
GO
ALTER TABLE [dbo].[tblUserIPLogs] ADD CONSTRAINT [DF_tblUserIPLogs_LoginDate] DEFAULT (sysutcdatetime()) FOR [LoginDate]
GO
ALTER TABLE [dbo].[tblUserTestIp] ADD CONSTRAINT [DF_tblUserIPLogs_LoggedIpAdress2] DEFAULT ('null') FOR [LoggedIpAdress]
GO
ALTER TABLE [dbo].[tblUserTestIp] ADD CONSTRAINT [DF_tblUserIPLogs_LoginDate2] DEFAULT (sysutcdatetime()) FOR [LoginDate]
GO
ALTER TABLE [dbo].[tblUserTestIpUnique] ADD CONSTRAINT [DF_tblUserIPLogs_LoggedIpAdress3] DEFAULT ('null') FOR [LoggedIpAdress]
GO
ALTER TABLE [dbo].[tblUserTestIpUnique] ADD CONSTRAINT [DF_tblUserIPLogs_LoginDate3] DEFAULT (sysutcdatetime()) FOR [LoginDate]
GO
一些例子...
适当的:
不适当的:
在 OLAP 系统中的维度表中 - 您希望使您的维度键尽可能小,以便您的事实表尽可能小(和快速)。
在您不确定组合是否唯一时。尽管这是一个相当糟糕的例子,但“人员”表将是多列 PK 的不良选择。
一个适用的例子是当你有一个连接不同表格的外键字段链接表。
一般来说,尽可能使用现有的、标识字段作为主键是个好主意。如果你没有自然的id字段,而且你需要组合很多字段才能得到唯一的PK,那么使用自动编号可能更好。主键超过两个字段会变得混乱。