由于您编辑后的输入格式与之前发布的格式有很大不同,因此我在很大程度上替换了先前的答案。这导致解决方案有所不同。
由于每行后面都没有换行符,要确定一行的确切结束位置,唯一的方法是要求每行具有与表头相同数量的列。至少,如果您不想依赖于某些可能脆弱的空格约定(即行分隔符是唯一一个未在空格前面加上
|的字符),那么只能这样做。您的问题至少没有将其作为行分隔符的规范提供。
以下的“解析器”提供了至少可以从您的格式说明和示例字符串中推导出的错误处理有效性检查,并允许没有行的表格。注释解释了它正在进行的基本步骤。
public class TableParser
{
const StringSplitOptions SplitOpts = StringSplitOptions.None;
const string RowColSep = "|";
static readonly string[] HeaderColSplit = { "||" };
static readonly string[] RowColSplit = { RowColSep };
static readonly string[] MLColSplit = { @"\\" };
public class TableRow
{
public List<string[]> Cells;
}
public class Table
{
public string[] Header;
public TableRow[] Rows;
}
public static Table Parse(string text)
{
var headerSplit = text.Split(HeaderColSplit, SplitOpts);
Ensure(headerSplit.Length > 1, "At least 1 header column is required in the input");
var hasRows = headerSplit.Last().IndexOf(RowColSep) >= 0;
var header = headerSplit.Skip(1)
.Take(headerSplit.Length - (hasRows ? 2 : 1))
.Select(c => c.Trim())
.ToArray();
if (!hasRows)
return new Table() { Header = header, Rows = new TableRow[0] };
var rowsCols = headerSplit.Last().Split(RowColSplit, SplitOpts);
Ensure((rowsCols.Length % (header.Length + 1)) == 1,
"The number of row colums does not match the number of header columns");
var rows = new TableRow[(rowsCols.Length - 1) / (header.Length + 1)];
for (int ri = 0, start = 1; ri < rows.Length; ri++, start += header.Length + 1)
{
rows[ri] = new TableRow() {
Cells = rowsCols.Skip(start).Take(header.Length)
.Select(c => c.Split(MLColSplit, SplitOpts).Select(p => p.Trim()).ToArray())
.ToList()
};
};
return new Table { Header = header, Rows = rows };
}
private static void Ensure(bool check, string errorMsg)
{
if (!check)
throw new InvalidDataException(errorMsg);
}
}
当以这种方式使用时:
public static void Main(params string[] args)
{
var wikiLine = @"|| Owner|| Action || Status || Comments || | Bill\\ | fix the lobby |In Progress | This is eary| | Joe\\ |fix the bathroom\\ | In progress| plumbing \\Electric \\Painting \\ \\ | | Scott \\ | fix the roof \\ | Complete | this is expensive|";
var table = TableParser.Parse(wikiLine);
Console.WriteLine(string.Join(", ", table.Header));
foreach (var r in table.Rows)
Console.WriteLine(string.Join(", ", r.Cells.Select(c => string.Join(Environment.NewLine + "\t# ", c))));
}
它将产生以下输出:
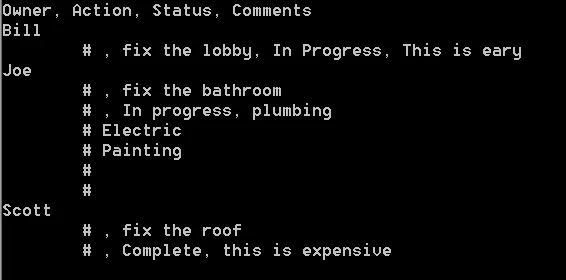
其中"\t# "表示由输入中的\\引起的换行符。
