使用图形数据库方法,我们可以使用infiniteGraph图形数据库和DO查询语言。我们创建一个权重计算器,然后在查询中使用它,查询应该如下所示:
CREATE WEIGHT CALCULATOR shortestRoute {
minimum: 0,
default: 0,
edges: {
()-[r:Road]->(): r.distance
}
};
Match m = max weight 8.0 shortestRoute
((:Town {name == 'A'})-[*..10]->(t:Town))
GROUP BY t.name
RETURN t.name as Name;
在此查询中,我们指定了“最大重量”为8.0以及要使用的WEIGHT CALCULATOR。然后,我们指定起始城镇{name == 'A'}和我们想要走出的度数[*..10]。然后,我们指定终点(t:Town),没有谓词,它是标签为“t”的类型为Town的节点。我们按t.name分组,并将t.name作为NAME返回。
此查询中使用的图形为:
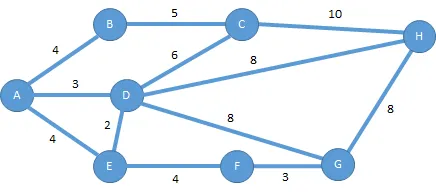
查询结果如下:
DO> Match m = max weight 8.0 shortestRoute ((:Town {name == 'A'})-[*..10]->(t:Town)) GROUP BY t.name RETURN t.name as Name;
{
_Projection
{
Name:'B'
},
_Projection
{
Name:'D'
},
_Projection
{
Name:'E'
},
_Projection
{
Name:'F'
}
}
设置(模式和示例数据)如下:
UPDATE SCHEMA {
CREATE CLASS Town {
name : STRING,
roadsIn : List { Element: Reference { EdgeClass: Road, EdgeAttribute: from }, CollectionTypeName: TreeListOfReferences },
roadsOut : List { Element: Reference { EdgeClass: Road, EdgeAttribute: to }, CollectionTypeName: TreeListOfReferences }
}
CREATE CLASS Road {
name : String,
from : Reference { referenced: Town, Inverse: roadsOut },
to : Reference { referenced: Town, Inverse: roadsIn },
distance : REAL { Storage: B32 },
avgTravelTime : REAL { Storage: B32 },
stopLightCount : INTEGER { Encoding: Signed, Storage: B16 }
}
};
let townA = create Town { name: "A" };
let townB = create Town { name: "B" };
let townC = create Town { name: "C" };
let townD = create Town { name: "D" };
let townE = create Town { name: "E" };
let townF = create Town { name: "F" };
let townG = create Town { name: "G" };
let townH = create Town { name: "H" };
let ab = create Road { name: "AB", distance: 4.0, stopLightCount: 1, from: $townA, to: $townB };
let bc = create Road { name: "BC", distance: 5.0, stopLightCount: 2, from: $townB, to: $townC };
let cd = create Road { name: "CD", distance: 6.0, stopLightCount: 3, from: $townC, to: $townD };
let cH = create Road { name: "CH", distance: 10.0, stopLightCount: 0, from: $townC, to: $townH };
let ad = create Road { name: "AD", distance: 3.0, stopLightCount: 0, from: $townA, to: $townD };
let ae = create Road { name: "AE", distance: 4.0, stopLightCount: 3, from: $townA, to: $townE };
let ed = create Road { name: "ED", distance: 2.0, stopLightCount: 1, from: $townE, to: $townD };
let ef = create Road { name: "EF", distance: 4.0, stopLightCount: 7, from: $townE, to: $townF };
let fg = create Road { name: "FG", distance: 3.0, stopLightCount: 0, from: $townF, to: $townG };
let dg = create Road { name: "DG", distance: 8.0, stopLightCount: 6, from: $townD, to: $townG };
let dH = create Road { name: "DH", distance: 8.0, stopLightCount: 9, from: $townD, to: $townH };
let gH = create Road { name: "GH", distance: 8.0, stopLightCount: 4, from: $townG, to: $townH };
查询对可能的结果路径进行快速/早期修剪,因此仅加载其需要的数据以确定结果。
(纬度,经度)或其他坐标来表示节点,然后将它们投入KD树中,以便快速检索。在大多数情况下,您最终会使用欧几里得距离而不是任意图形权重,但这可能是一个很好的近似值。维基页面底部有许多链接,可用于实现KD树。 - Nicu Stiurca