请注意,我问的不是如何,而是为什么。我不知道这是RCP特定的问题还是Java固有的问题。
我的Java源文件编码为UTF-8。
如果我像这样定义字面字符串:
这样做没有问题(我的其他字符串都在属性文件中,只有语言名称是硬编码的),但我想了解一下。
我认为编译器在构建字节码时必须转换Java文字字符串。那么为什么需要Unicode转义?在Java源文件中使用高范围的Unicode字符是错误的吗?这些字符在编译时会发生什么,与转义字符的处理有何不同?这个问题只是与RCP缓存相关吗?
我的Java源文件编码为UTF-8。
如果我像这样定义字面字符串:
new Language("fr", "Français"),
new Language("zh", "中文")
当我从Eclipse启动应用程序并在应用程序中使用该字符串时,它按照我的预期工作:
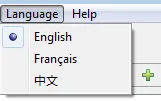
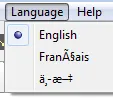
我使用的解决方案是像这样转义字符:
new Language("fr", "Fran\u00e7ais"), // Français
new Language("zh", "\u4e2d\u6587") // 中文
这样做没有问题(我的其他字符串都在属性文件中,只有语言名称是硬编码的),但我想了解一下。
我认为编译器在构建字节码时必须转换Java文字字符串。那么为什么需要Unicode转义?在Java源文件中使用高范围的Unicode字符是错误的吗?这些字符在编译时会发生什么,与转义字符的处理有何不同?这个问题只是与RCP缓存相关吗?
eclipse.ini中的-Dfile.encoding=UTF8)? - Matt Ball