我想用RGBA颜色值来表示一个32位的数字,使用联合体生成该数字的值是否可移植?考虑以下C代码;
这个可以成功编译,我希望使用它来替代一堆函数,但这样安全吗?
union pixel {
uint32_t value;
uint8_t RGBA[4];
};
这个可以成功编译,我希望使用它来替代一堆函数,但这样安全吗?
union pixel {
uint32_t value;
uint8_t RGBA[4];
};
这被称为"类型转换", 由于字节序问题,它不是直接可移植的。然而,除此之外,这样做是没有问题的。 C标准在说明这是可以的方面并不十分明确,但显然是可以的。请阅读这些答案和来源:
此外,C18草案N2176 ISO/IEC 9899:2017在“6.5.2.3结构和联合成员”一节的脚注97中指出:
如果一个成员曾经读取了联合对象的内容,而不是上次用于存储值的成员,则将该值的对象表示中的适当部分重新解释为新类型的对象表示,如6.2.6所述(有时称为“类型游戏”)。 这可能会产生陷阱表示。请参见此处的屏幕截图:
因此,拥有
typedef union my_union_u
{
uint32_t value;
/// A byte array large enough to hold the largest of any value in the union.
uint8_t bytes[sizeof(uint32_t)];
} my_union_t;
value转换为bytes的手段,在C语言中是可以的。在C++中,它作为GNU gcc扩展而工作(但不属于C++标准的一部分)。请参见@Christoph在此处回答中的解释:
GNU对标准C++(和C90)的扩展明确允许使用union进行类型转换。其他不支持GNU扩展的编译器也可能支持union类型转换,但这并不是基础语言标准的一部分。
下载代码:您可以从我的eRCaGuy_hello_world存储库中下载并运行下面的所有代码:"type_punning.c"。C和C++的gcc构建和运行命令都在文件顶部的注释中。
因此,您可以像这样读取uint32_t value中的单个字节:
技巧1:基于联合的类型转换(这是“类型转换”):
这就是“类型转换”的意思:将一种类型写入联合中,然后读出另一种类型,从而使用联合执行类型“转换”。
my_union_t u;
// write to uint32_t value
u.value = 1234;
// read individual bytes from uint32_t value
printf("1st byte = 0x%02X\n", (u.bytes)[0]);
printf("2nd byte = 0x%02X\n", (u.bytes)[1]);
printf("3rd byte = 0x%02X\n", (u.bytes)[2]);
printf("4th byte = 0x%02X\n", (u.bytes)[3]);
示例输出:
1st byte = 0xD2
2nd byte = 0x04
3rd byte = 0x00
4th byte = 0x00
1st byte = 0x00
2nd byte = 0x00
3rd byte = 0x04
4th byte = 0xD2
如果您想要的话,也可以使用原始指针来完成此操作,而无需使用联合体,如下所示:
技巧2:通过原始指针读取(这不是“类型转换”):
uint32_t value = 1234;
uint8_t *bytes = (uint8_t *)&value;
// read individual bytes from uint32_t value
printf("1st byte = 0x%02X\n", bytes[0]);
printf("2nd byte = 0x%02X\n", bytes[1]);
printf("3rd byte = 0x%02X\n", bytes[2]);
printf("4th byte = 0x%02X\n", bytes[3]);
样例输出:
1st byte = 0xD2
2nd byte = 0x04
3rd byte = 0x00
4th byte = 0x00
1st byte = 0x00
2nd byte = 0x00
3rd byte = 0x04
4th byte = 0xD2
为了避免上述 联合体类型转换 和 裸指针 方法存在的字节序问题,您可以使用以下类似方法。这样可以避免硬件架构之间的字节序差异:
技巧 3.1:使用位掩码和位移(这不是“类型转换”):
uint32_t value = 1234;
uint8_t byte0 = (value >> 0) & 0xff;
uint8_t byte1 = (value >> 8) & 0xff;
uint8_t byte2 = (value >> 16) & 0xff;
uint8_t byte3 = (value >> 24) & 0xff;
printf("1st byte = 0x%02X\n", byte0);
printf("2nd byte = 0x%02X\n", byte1);
printf("3rd byte = 0x%02X\n", byte2);
printf("4th byte = 0x%02X\n", byte3);
1st byte = 0xD2
2nd byte = 0x04
3rd byte = 0x00
4th byte = 0x00
或:
技巧 3.2:使用便捷宏进行位掩码和位移操作:
#define BYTE(value, byte_num) ((uint8_t)(((value) >> (8*(byte_num))) & 0xff))
uint32_t value = 1234;
uint8_t byte0 = BYTE(value, 0);
uint8_t byte1 = BYTE(value, 1);
uint8_t byte2 = BYTE(value, 2);
uint8_t byte3 = BYTE(value, 3);
// OR
uint8_t bytes[] = {
BYTE(value, 0),
BYTE(value, 1),
BYTE(value, 2),
BYTE(value, 3),
};
printf("1st byte = 0x%02X\n", byte0);
printf("2nd byte = 0x%02X\n", byte1);
printf("3rd byte = 0x%02X\n", byte2);
printf("4th byte = 0x%02X\n", byte3);
printf("---------------\n");
printf("1st byte = 0x%02X\n", bytes[0]);
printf("2nd byte = 0x%02X\n", bytes[1]);
printf("3rd byte = 0x%02X\n", bytes[2]);
printf("4th byte = 0x%02X\n", bytes[3]);
1st byte = 0xD2
2nd byte = 0x04
3rd byte = 0x00
4th byte = 0x00
---------------
1st byte = 0xD2
2nd byte = 0x04
3rd byte = 0x00
4th byte = 0x00
(my_pixel.RGBA)[0]或(u.bytes)[0]可能等于上面我定义的byte0,如果架构是大端的,则可能等于byte3。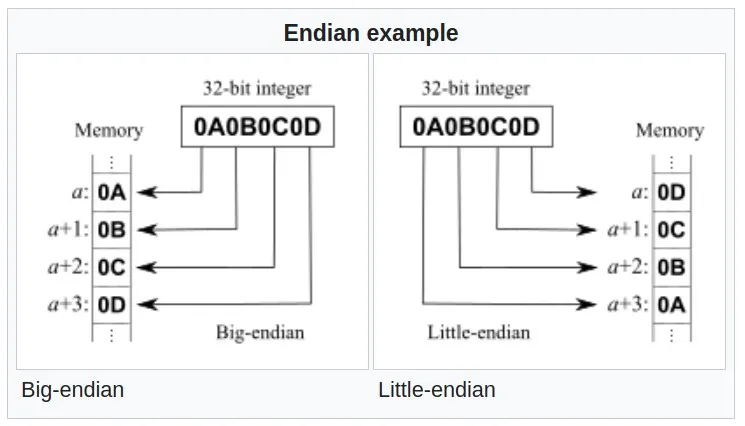
根据维基百科的“类型切换”文章,写入联合成员value但从RGBA[4]读取是“未指定的行为”。然而,@Eric Postpischil在他下面的评论中指出,维基百科是错误的。本答案顶部的其他参考资料也与维基百科现在的回答不一致。
Eric Postpischil的评论,我现在理解并同意,强调说(重点添加):
引用的文字,关于字节对应于存储在最后一个联合成员之外的成员,不适用于此情况。它适用于这样一种情况:例如,写入一个两字节的short成员和读取一个四字节的int成员。多出来的两个字节是未指定的。这使得C实现有权将store到short作为两字节存储(保留联合的其余字节不变),或者作为四字节存储(可能因为对于处理器而言更有效率)。在手头的情况下,我们有一个四字节的uint32_t成员和一个四字节的uint8_t [4]成员。
维基百科声称(截至2021年4月22日):
对于union:
union {
unsigned int ui;
float d;
} my_union = { .d = x };
my_union.d 后,仍然访问 my_union.ui 是 C 语言中的类型转换 [4],其结果是未指定行为 [5](在 C++ 中则为未定义行为 [6])。从上述引用[5]中可得知:"未指定行为" 包括以下内容:
这意味着,如果您将数据存储到联合的一个成员中,但从另一个成员中读取,而这正是您想要使用该联合的情况,那么根据C标准,这是“未指定的行为”。与最后存储的成员变量不同的联合成员对应的字节的值 (6.2.6.1)。

我认为gcc允许类型转换(将数据写入联合体的一个成员,但从联合体的另一个成员读取数据,作为一种“翻译”的形式),作为“gcc扩展”,但是如果在构建标志中使用-Wpedantic,C和C ++标准将禁止它。
READ_BYTE()作为宏。