如何理解强化学习中的近端策略优化算法(Proximal Policy Optimization Algorithm)?
1
从原始的PPO论文中:
我们引入了[PPO],一系列使用多个时期的随机梯度上升来执行每个策略更新的策略优化方法。这些方法具有信任区域[TRPO]方法的稳定性和可靠性,但实现起来要简单得多,只需要对香草策略梯度实现进行少量代码更改,适用于更一般的设置(例如,在使用策略和值函数的联合架构时),并具有更好的整体性能。
1. Clipped Surrogate Objective
Clipped Surrogate Objective是策略梯度目标的替代品,旨在通过限制每次步骤中对策略的更改来提高训练稳定性。
对于普通策略梯度(例如REINFORCE)——在阅读本文之前,您应该熟悉它们——用于优化神经网络的目标如下:
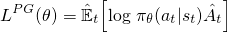
香草策略梯度方法使用您的动作的对数概率(log π(a|s))来跟踪影响动作的影响,但您可以想象使用另一个函数来完成此操作。另一个这样的函数是在this paper中介绍的,它使用当前策略下的动作概率(π(a|s))除以之前策略下的动作概率(π_old(a|s))。如果您熟悉重要性采样,那么这看起来有点类似。
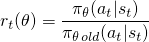
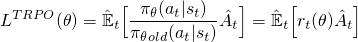
与其添加所有这些额外的功能,不如将这些稳定性特性构建到目标函数中。你可能会猜到,这就是PPO所做的。它获得了与TRPO相同的性能优势,并通过优化这个简单(但有点滑稽的)Clipped Surrogate Objective来避免复杂性。
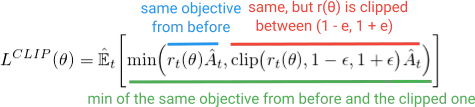
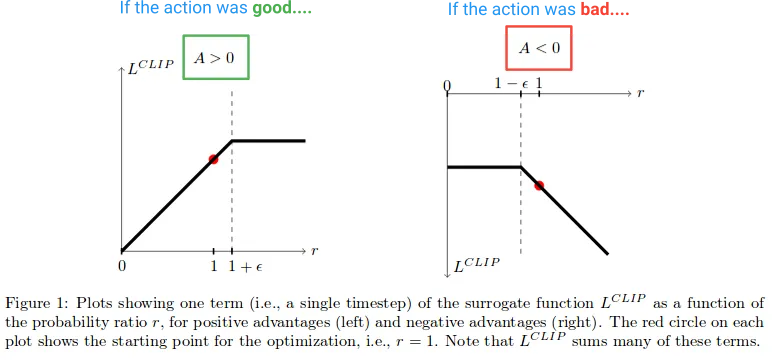
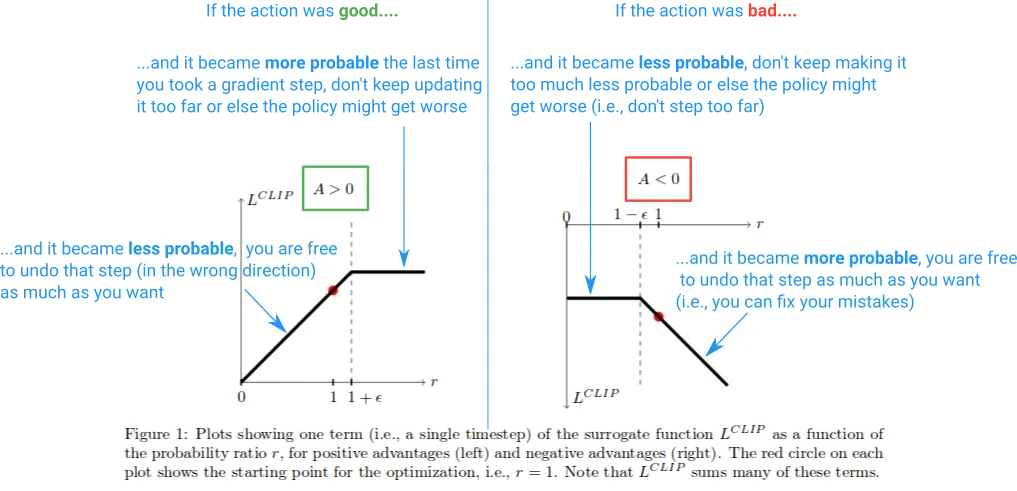
但为什么我们要让图表右侧的r(θ)无限增长呢?这起初似乎有些奇怪,但在这种情况下,是什么导致了r(θ)的大幅增长呢?
在该区域中,r(θ)的增长是由于梯度步骤使我们的操作变得更加可能,并且这导致我们的策略变得更差。如果是这种情况,我们希望能够撤消该梯度步骤。不过,恰好L剪辑函数可以实现这一点。在此处,该函数是负数,因此梯度将指示我们向另一个方向走,并通过与我们失误程度成比例的量减少行动的可能性。(请注意,在图表的远左侧也有类似的区域,在那里,行动是正确的,但我们却错误地减少了其可能性。)
这些“撤消”区域解释了为什么我们必须在目标函数中包含奇怪的最小化项。它们对应于未剪辑的r(θ)A具有较低价值并被最小化返回的部分。这是因为它们是朝着错误的方向迈出的步骤(例如,行动是正确的,但我们却无意中降低了其可能性)。如果我们没有在目标函数中包含min,那么这些区域将是平坦的(梯度=0),我们将无法纠正错误。
下面是一个总结的图表:
与vanilla policy gradient方法不同,由于Clipped Surrogate Objective函数,PPO允许您在样本上运行多个梯度上升阶段,而不会引起破坏性的大策略更新。这使您可以从数据中挤出更多内容并减少样本效率低下。PPO使用N个并行演员运行策略,每个演员都收集数据,然后它从这些数据中采样小批量进行K次训练,使用Clipped Surrogate Objective函数。请参见下面的完整算法(近似参数值为:K=3-15,M=64-4096,T(地平线)=128-2048):

并行演员的部分是由A3C论文推广的,并已成为一种收集数据的相当标准的方式。
新颖的部分是它们能够在轨迹样本上运行K个梯度上升时期。正如他们在论文中所述,运行香草策略梯度优化多次以从每个样本中学习更多将是很好的。然而,对于香草方法来说,这通常在实践中失败,因为它们在本地样本上采取的步骤太大了,这破坏了策略。另一方面,PPO具有内置机制来防止过度更新。
对于每次迭代,在使用π_old(第3行)采样环境并且我们开始运行优化(第6行)后,我们的策略π将完全等于π_old。因此,起初,我们的更新都不会被剪切,并保证从这些示例中学到一些东西。但是,随着我们使用多个时期更新π,目标将开始达到剪辑限制,那些样本的梯度将变为0,并且训练将逐渐停止...直到我们进入下一个迭代并收集新的样本为止。
....
现在就介绍这些。如果您对此更加了解感兴趣,我建议您深入研究原始论文,尝试自己实现它,或者深入基准实现并玩弄代码。[编辑:2019/01/27]:为了更好地了解PPO与其他强化学习算法的关系和背景,我也强烈推荐查看OpenAI的Spinning Up资源和实现。
13
PPO和TRPO试图在每次策略更新之间谨慎地更新策略,而不会对其性能产生不利影响。
为了做到这一点,需要一种方法来衡量每次更新后策略的变化程度。这通过查看更新策略和旧策略之间的KL离散度来完成。
这变成了一个受限优化问题,我们希望在最大性能的方向上改变策略,遵循新旧策略之间的KL离散度不超过某个预定义(或自适应)阈值的约束条件。
使用TRPO时,在更新期间计算KL约束,并找到解决此问题的学习率(通过Fisher矩阵和共轭梯度)。这样做有点麻烦。
使用PPO时,我们通过将KL离散度从约束条件转换为惩罚项来简化问题,类似于例如L1、L2加权惩罚(以防止权重增长到较大值)。PPO通过在小范围内硬剪辑策略比率(更新策略与旧策略的比率),消除了完全计算KL分歧的需求,其中1.0表示新策略与旧策略相同。
PPO是一个简单的算法,属于策略优化算法类(与DQN等基于价值的方法相反)。如果你“了解”强化学习基础知识(我的意思是至少认真阅读过Sutton's book的前几章),那么第一步就是熟悉策略梯度算法。你可以阅读this paper或Sutton's book新版的第13章。此外,你还可以阅读PPO的第一作者之前的工作this paper关于TRPO的研究(这篇论文存在许多符号错误,请注意)。希望能有所帮助。 --Mehdi
我认为对于像Cartpole-v1这样的离散动作空间,实现起来比连续动作空间更容易。但是对于连续动作空间,这是我在Pytorch中找到的最直接的实现,因为你可以清楚地看到他们如何获得mu和std,而我在更著名的实现(如Openai Baselines、Spinning up或Stable Baselines)中却无法做到这一点。
以上内容摘自上述链接。
class ActorCritic(nn.Module):
def __init__(self, num_inputs, num_outputs, hidden_size, std=0.0):
super(ActorCritic, self).__init__()
self.critic = nn.Sequential(
nn.Linear(num_inputs, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 1)
)
self.actor = nn.Sequential(
nn.Linear(num_inputs, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, num_outputs),
)
self.log_std = nn.Parameter(torch.ones(1, num_outputs) * std)
self.apply(init_weights)
def forward(self, x):
value = self.critic(x)
mu = self.actor(x)
std = self.log_std.exp().expand_as(mu)
dist = Normal(mu, std)
return dist, value
以及剪辑:
def ppo_update(ppo_epochs, mini_batch_size, states, actions, log_probs, returns, advantages, clip_param=0.2):
for _ in range(ppo_epochs):
for state, action, old_log_probs, return_, advantage in ppo_iter(mini_batch_size, states, actions, log_probs, returns, advantages):
dist, value = model(state)
entropy = dist.entropy().mean()
new_log_probs = dist.log_prob(action)
ratio = (new_log_probs - old_log_probs).exp()
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1.0 - clip_param, 1.0 + clip_param) * advantage
我在Youtube视频评论区上方找到了以下链接:
原文链接