我正在尝试给一个将 .bmp 转换为灰度 .bmp 的程序添加并行处理。然而,我发现并行处理的性能通常比串行处理差 2-4 倍。我已经调整了 parBuffer/chunking 大小,但是还是无法理解原因。我需要一些指导。
这里使用的整个源文件链接如下:http://lpaste.net/106832 我们使用 Codec.BMP 来读取由 type RGBA = (Word8, Word8, Word8, Word8) 表示的像素流。要将其转换为灰度图像,只需对所有像素映射一个“亮度”变换即可。
串行实现非常简单:
但这仍然不能产生理想的性能表现:
这里使用的整个源文件链接如下:http://lpaste.net/106832 我们使用 Codec.BMP 来读取由 type RGBA = (Word8, Word8, Word8, Word8) 表示的像素流。要将其转换为灰度图像,只需对所有像素映射一个“亮度”变换即可。
串行实现非常简单:
toGray :: [RGBA] -> [RGBA]
toGray x = map luma x
测试输入的 .bmp 文件大小为 5184 x 3456(71.7 MB)。
串行实现需要约 10 秒,每个像素约 550 纳秒。Threadscope 显示运行情况良好:
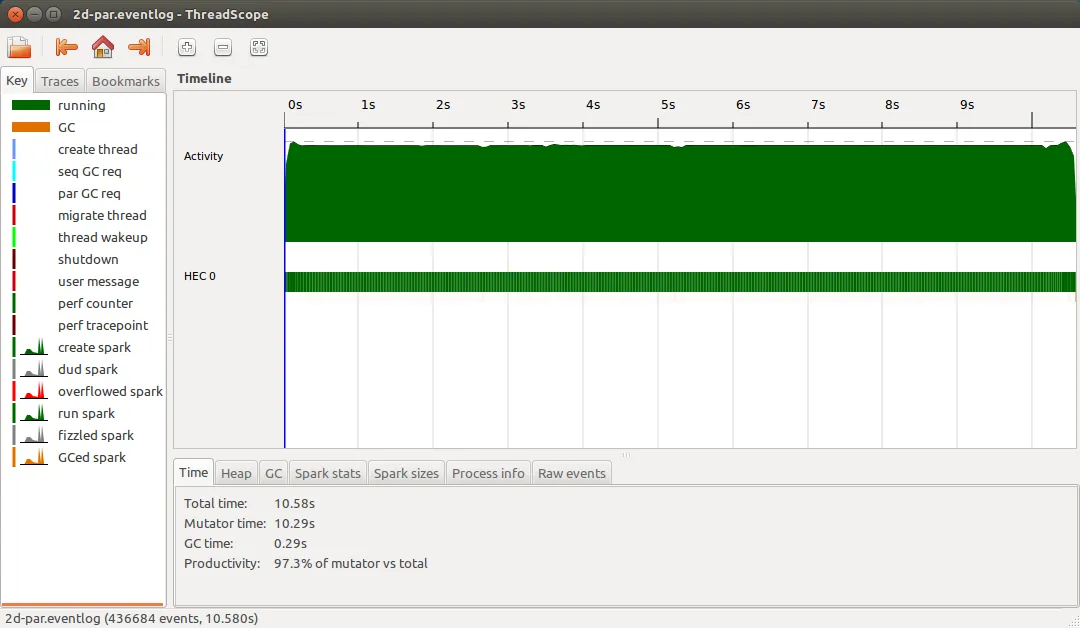
为什么速度这么快?我猜测这与惰性 ByteString 有关(即使 Codec.BMP 使用严格的 ByteString——这里是否发生了隐式转换?)和融合。
添加并行性
首次尝试添加并行性是通过 parList。但结果非常糟糕。程序使用了约 4-5GB 的内存,系统开始交换。
然后我阅读了 Simon Marlow 的 O'Reilly 书中的“使用 parBuffer 并行化惰性流”部分,并尝试使用大型大小的 parBuffer。但这仍然没有产生理想的性能。火花大小非常小。
然后我尝试通过对惰性列表进行分块然后继续使用 parBuffer 进行并行处理来增加火花大小:
toGrayPar :: [RGBA] -> [RGBA]
toGrayPar x = concat $ (withStrategy (parBuffer 500 rpar) . map (map luma))
(chunk 8000 x)
chunk :: Int -> [a] -> [[a]]
chunk n [] = []
chunk n xs = as : chunk n bs where
(as,bs) = splitAt (fromIntegral n) xs
但这仍然不能产生理想的性能表现:
18,934,235,760 bytes allocated in the heap
15,274,565,976 bytes copied during GC
639,588,840 bytes maximum residency (27 sample(s))
238,163,792 bytes maximum slop
1910 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 35277 colls, 35277 par 19.62s 14.75s 0.0004s 0.0234s
Gen 1 27 colls, 26 par 13.47s 7.40s 0.2741s 0.5764s
Parallel GC work balance: 30.76% (serial 0%, perfect 100%)
TASKS: 6 (1 bound, 5 peak workers (5 total), using -N2)
SPARKS: 4480 (2240 converted, 0 overflowed, 0 dud, 2 GC'd, 2238 fizzled)
INIT time 0.00s ( 0.01s elapsed)
MUT time 14.31s ( 14.75s elapsed)
GC time 33.09s ( 22.15s elapsed)
EXIT time 0.01s ( 0.12s elapsed)
Total time 47.41s ( 37.02s elapsed)
Alloc rate 1,323,504,434 bytes per MUT second
Productivity 30.2% of total user, 38.7% of total elapsed
gc_alloc_block_sync: 7433188
whitehole_spin: 0
gen[0].sync: 0
gen[1].sync: 1017408
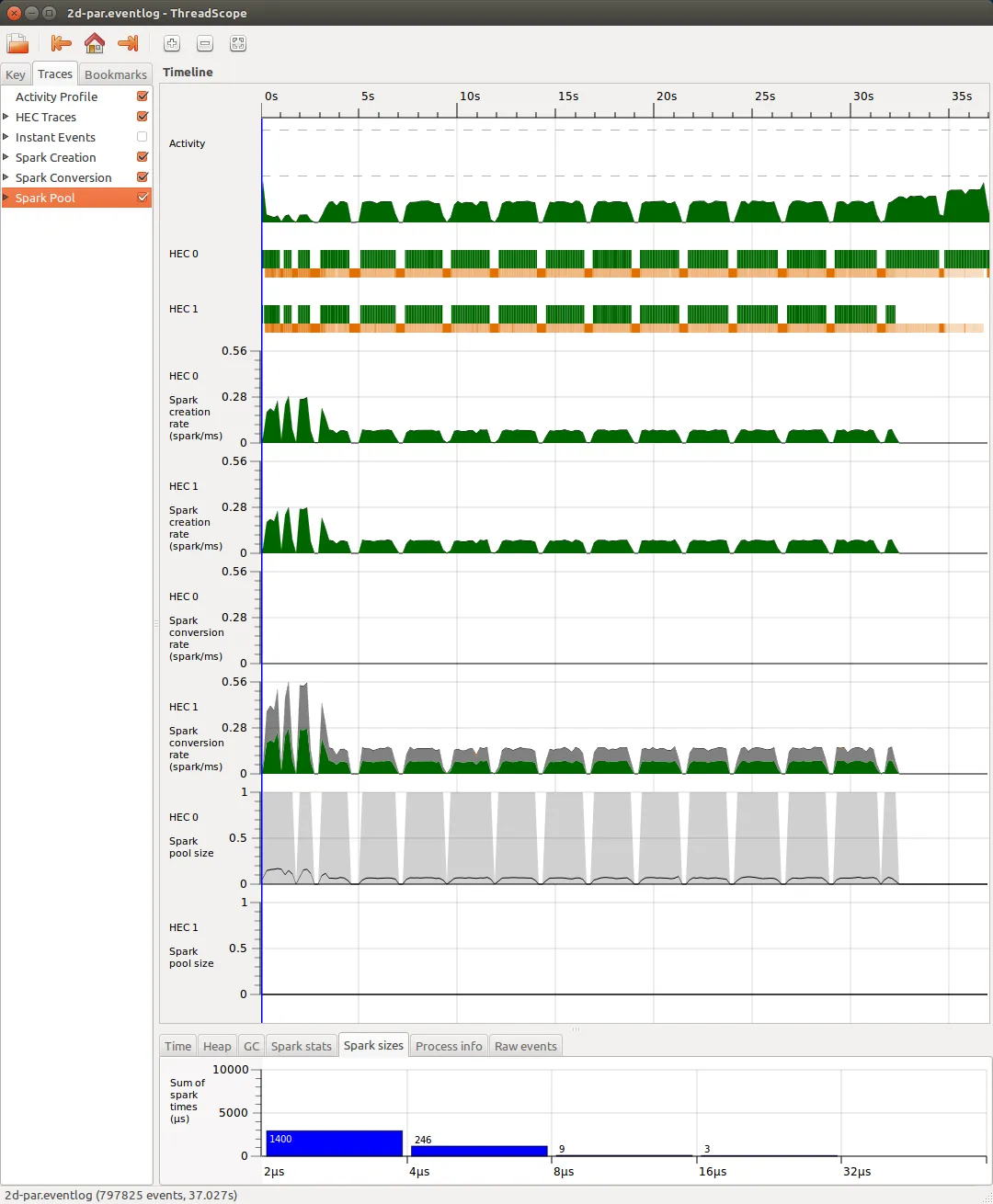
我该如何更好地理解这里正在发生的事情?
[RGBA]长度需要多长时间?由于您的其他评论表明该值正在使用惰性IO流式传输,因此IO时间很可能始终主导您所做的任何处理,无论是否并行。那么运行时间的多少是仅IO和解析的时间? - Carl