我已经为旅行商问题编写了一个蛮力搜索算法,并测试了不同数量的“城市”所需的时间。从下面的图表中,我们可以看到时间大致与
我的问题是,是否仍然正确地说该算法的运行时间为
(n-1)!成正比,其中n是“城市”的数量。它不是直接与n!成正比的(毕竟,(n-1)! = n! / n)。我的问题是,是否仍然正确地说该算法的运行时间为
O(n!),还是更好地说O((n-1)!)?我以前从未见过后者,但它似乎更准确。我在这里有些误解了。
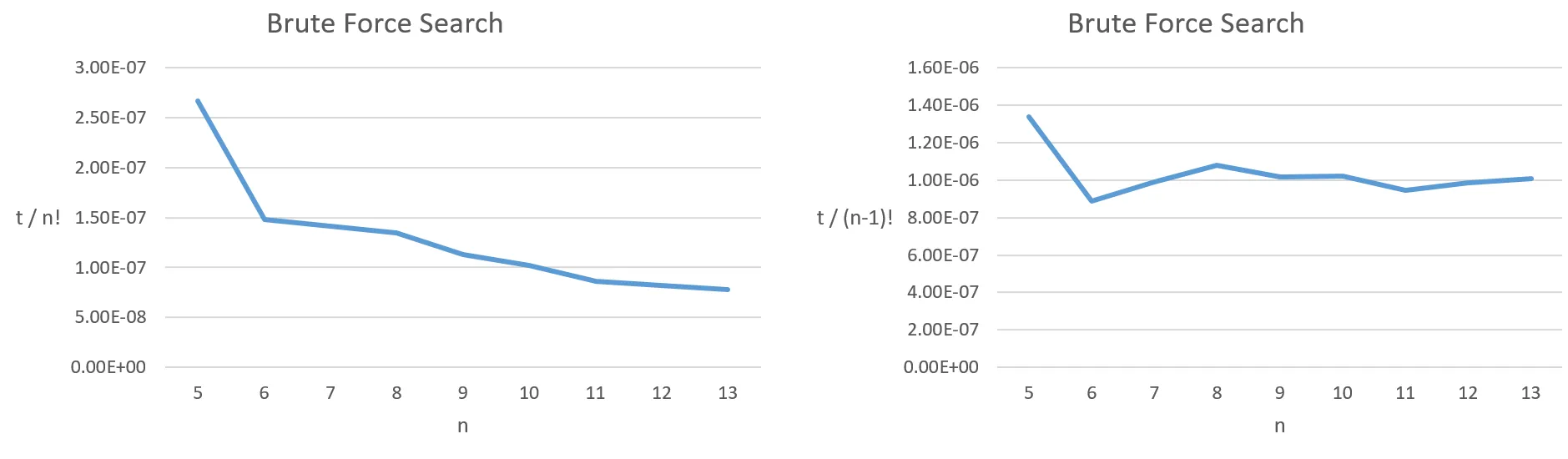
[t = 花费时间, n = 城市数量]