假设有一个如下结构的表格:
该目标是计算在任何给定时间段内处于活动状态的总行数的最大值(即在
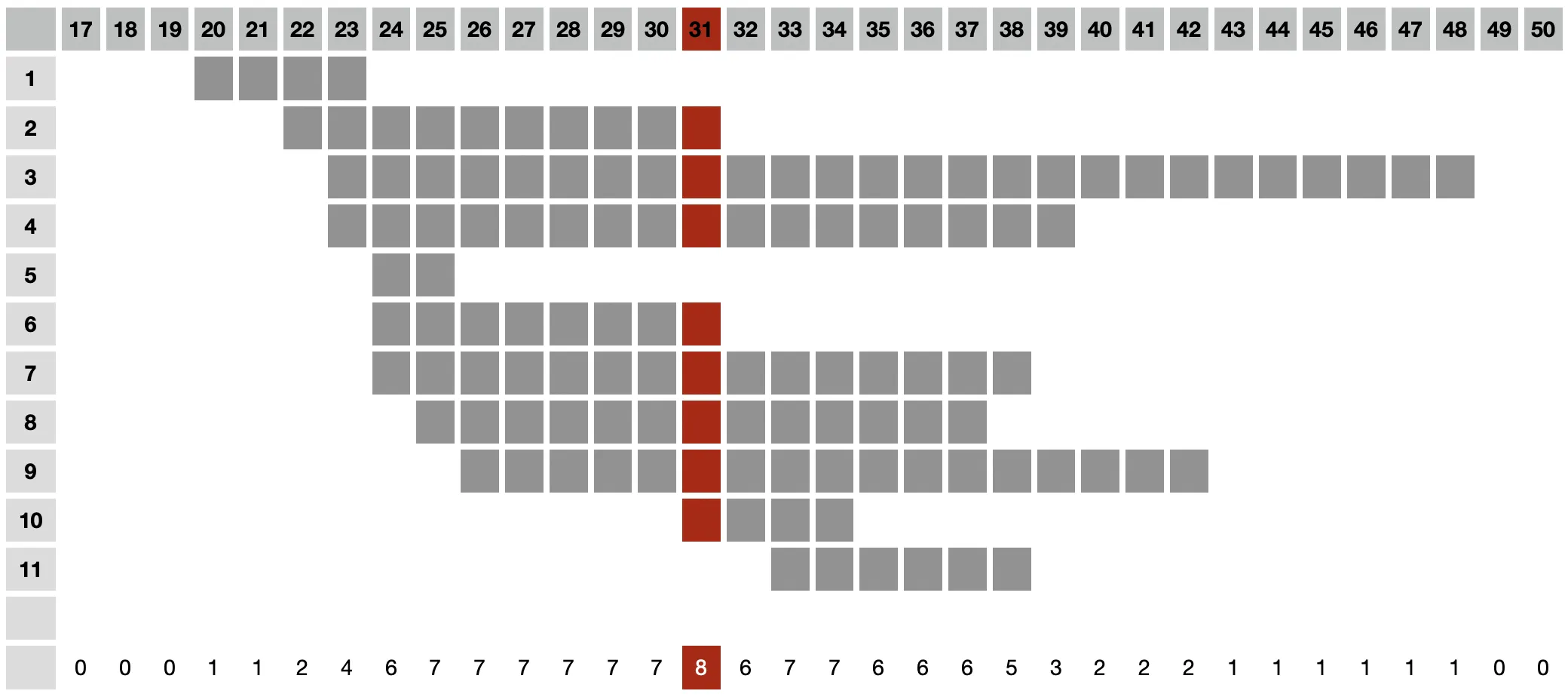
根据上述示例,此最大值将为8,并将对应于00:31时间戳,其中活动行为2、3、4、6、7、8、9、10(如下所示模式)。
id start end
--------------------
01 00:18 00:23
02 00:22 00:31
03 00:23 00:48
04 00:23 00:39
05 00:24 00:25
06 00:24 00:31
07 00:24 00:38
08 00:25 00:37
09 00:26 00:42
10 00:31 00:34
11 00:33 00:38
该目标是计算在任何给定时间段内处于活动状态的总行数的最大值(即在
start和end之间)。使用过程性算法可以相对容易地实现,但我不确定如何在SQL中执行此操作。根据上述示例,此最大值将为8,并将对应于00:31时间戳,其中活动行为2、3、4、6、7、8、9、10(如下所示模式)。
select count(*) from time_tbl where '00:31'::time between start and end,假设start和end是time字段。 - Adrian Klaver