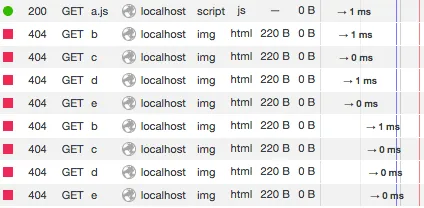
请将以下HTML保存为本地文件,例如
我没有在1234端口上运行服务器,所以请求甚至无法成功连接。
我期望的行为是所有请求都失败,并且完成它。
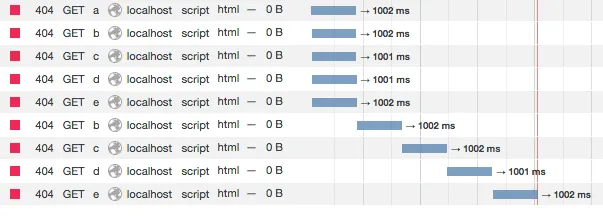
实际上,在Firefox中发生的是所有5个.js文件并行请求,它们无法连接,然后最后4个按顺序重新请求。就像这样:
然后重新加载了Firefox。它显示如下:
/tmp/foo.html,然后在Firefox中打开(我使用的是49.0.2版本)。<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<script src="http://localhost:1234/a.js"></script>
<script src="http://localhost:1234/b.js"></script>
<script src="http://localhost:1234/c.js"></script>
<script src="http://localhost:1234/d.js"></script>
<script src="http://localhost:1234/e.js"></script>
</body>
</html>
我没有在1234端口上运行服务器,所以请求甚至无法成功连接。
我期望的行为是所有请求都失败,并且完成它。
实际上,在Firefox中发生的是所有5个.js文件并行请求,它们无法连接,然后最后4个按顺序重新请求。就像这样:
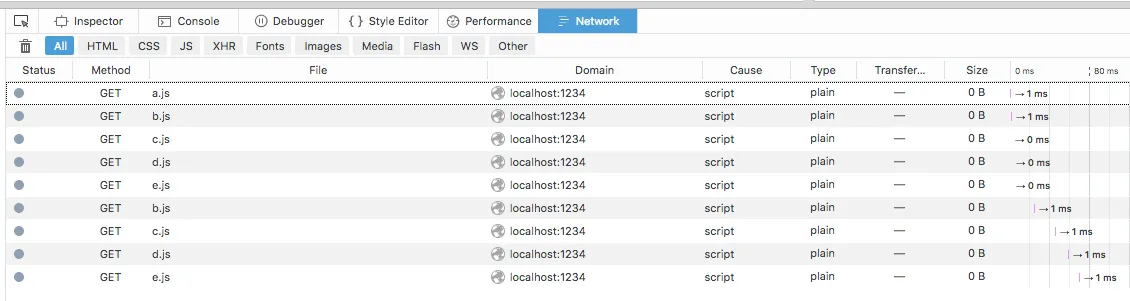
为什么?
如果我在1234上启动一个总是404的服务器,行为是相同的。
这个特定的例子在Chrome中没有重现相同的行为,但其他类似的例子是我最初发现这种行为的方式。
编辑:这是我测试它在404时发生的方式。
$ cd /tmp
$ mkdir empty
$ cd empty
$ python -m SimpleHTTPServer 1234
然后重新加载了Firefox。它显示如下:
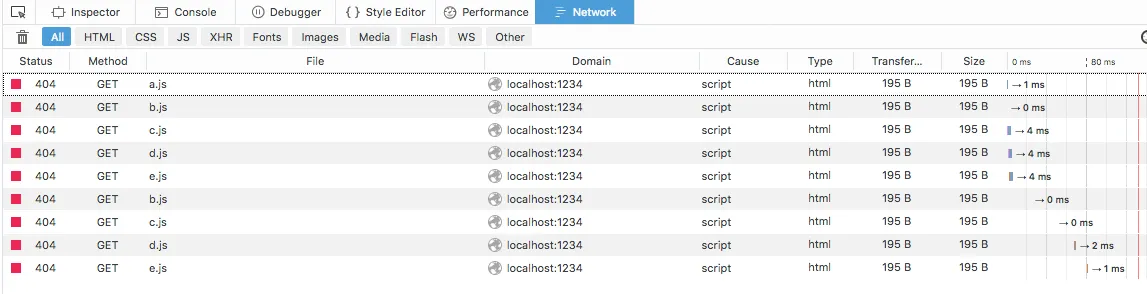
服务器实际上也看到了所有这些请求(前5个请求由于并行请求而无序,但最后4个请求始终是b、c、d、e,因为它们在串行中重新请求)。
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /d.js HTTP/1.1" 404 -
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /c.js HTTP/1.1" 404 -
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /b.js HTTP/1.1" 404 -
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /a.js HTTP/1.1" 404 -
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /e.js HTTP/1.1" 404 -
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /b.js HTTP/1.1" 404 -
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /c.js HTTP/1.1" 404 -
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /d.js HTTP/1.1" 404 -
127.0.0.1 - - [02/Nov/2016 13:25:40] code 404, message File not found
127.0.0.1 - - [02/Nov/2016 13:25:40] "GET /e.js HTTP/1.1" 404 -