从采样率为44,100 kHz、量化位深度为16位的立体声wav文件开始,你就拥有了一份标准的CD音质文件... 发出以下命令行以显示文件的统计信息
ffprobe Cesária_Évora.wav
典型输出
Duration: 00:00:21.51, bitrate: 1411 kb/s
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 44100 Hz, 2 channels, s16, 1411 kb/s
从wav问题创建PCM文件
ffmpeg -i Cesária_Évora.wav -f s16le -acodec pcm_s16le cesaria.dat
请注意,WAV文件仅由44个字节的头部和随后的有效载荷组成,该有效载荷以PCM格式表示原始音频曲线...这个PCM文件严格为L1 R1 L2 R2,没有多余内容...任何帧的概念都是我们解析数据的抽象,没有比特用于实现帧(如起始/结束标记)...编写操作PCM数据的代码时,请牢记您的位深度以及文件是否具有小端或大端字节结构...每当您的文件具有8位的位深度时,您可以安全地忽略字节序,因为您永远不需要移动字节,但由于上述文件的位深度为16位,这意味着每个音频曲线点由每个通道的单个16位数字表示(立体声为两个通道,单声道为一个通道)
读取此类文件时,这个16位数字存储在两个字节中...如果是小端,则在读取字节时,最左边的字节(在您遍历文件时首次遇到的字节)是最小的字节,其次是下一个更重要的字节。
L1 R1 L2 R2
以下是音频曲线上两个16位点的立体声表示。
Llittle1 Lbig1 Rlittle1 Rbig1 Llittle2 Lbig2 Rlittle2 Rbig2
当我们谈论用于存储这两个点的单个字节时...上面的注释显示8个字节...同样,如果我们有一个24字节的位深度,对于一个通道上的一个原始音频样本,它将如下所示。
Llittle1 Lbigger1 Lbiggest1 Rlittle1 Rbigger1 Rbiggest1
概念上,当阅读一个16位比特深度的小端文件时,以下是解析单个通道在原始音频曲线上的一个点的PCM的方法:
Llittle1 Lbig1
现在要生成单个值L1,您可以按照以下方式进行概念上的操作
L1 = ( Lbig1 << shift 8 bits to left ) + Llittle1
我不确定这是否是您要找的抽象级别,但它是掌握数字音频的一个基石。
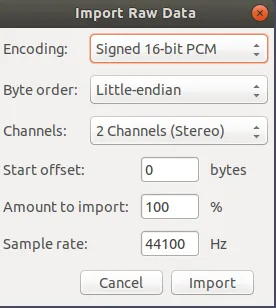
非常有用的工具Audacity允许您导入PCM格式的原始音频文件,就像我们上面生成的cesaria.dat一样... Audacity -> 文件 -> 导入 -> 原始数据 -> 选择cesaria.dat ->