我想要分割这些行:
<label>Olympic Games</label>
<title>Next stop</title>
到:
["<label>", "Olympic Games", "</label>"]
["<title>", "Next stop", "</title>"]
在Python中,我可以使用正则表达式,但我所创建的内容没有任何作用:
line.split("<\*>")
我想要分割这些行:
<label>Olympic Games</label>
<title>Next stop</title>
到:
["<label>", "Olympic Games", "</label>"]
["<title>", "Next stop", "</title>"]
在Python中,我可以使用正则表达式,但我所创建的内容没有任何作用:
line.split("<\*>")
re.split(r'(?<=>)(.+?)(?=<)', '<label>Olympic Games</label>')
<(label|title)>([^<]*)</(label|title)>
<(label|title)>([^<]*)</(\1)>
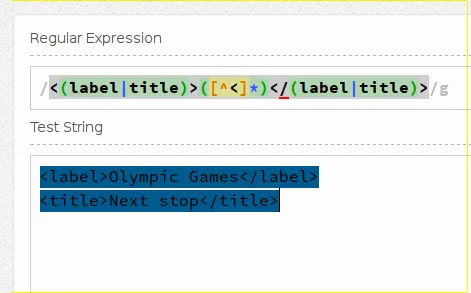
我使用了三个捕获组,如果您不需要它们,只需删除 ()
您的正则表达式 <\*> 的问题在于它只匹配一个内容:<*>。您使用 \* 转义了 *,因此您表示的是:
<,然后是一个 *,最后是一个 >。<(label|title)>([^<]*)</(\1)> 更好。 - cwallenpoole数据:
line = """<label>Olympic Games</label>
<title>Next stop</title>"""
使用具有前瞻/后顾断言的 re.findall:
import re
pattern = re.compile("(<.*(?<=>))(.*)((?=</)[^>]*>)")
print re.findall(pattern, line)
# [('<label>', 'Olympic Games', '</label>'), ('<title>', 'Next stop', '</title>')]
如果没有前瞻/后顾断言,只能通过捕获组并使用 re.findall 来实现:
pattern = re.compile("(<[^>]*>)(.*)(</[^>]*>)")
print re.findall(pattern, line)
# [('<label>', 'Olympic Games', '</label>'), ('<title>', 'Next stop', '</title>')]
如果你不介意标点符号,这里有一个快速的非正则表达式替代方案,使用itertools.groupby。
代码
import itertools as it
def split_at(iterable, pred, keep_delimter=False):
"""Return an iterable split by a delimiter."""
if keep_delimter:
return [list(g) for k, g in it.groupby(iterable, pred)]
return [list(g) for k, g in it.groupby(iterable, pred) if k]
演示
>>> words = "Lorem ipsum ..., consectetur ... elit, sed do eiusmod ...".split(" ")
>>> pred = lambda x: "elit" in x
>>> split_at(words, pred, True)
[['Lorem', 'ipsum', '...,', 'consectetur', '...'],
['elit,'],
['sed', 'do', 'eiusmod', '...']]
>>> words = "Lorem ipsum ..., consectetur ... elit, sed do eiusmod ...".split(" ")
>>> pred = lambda x: "consect" in x
>>> split_at(words, pred, True)
[['Lorem', 'ipsum', '...,'],
['consectetur'],
['...', 'elit,', 'sed', 'do', 'eiusmod', '...']]