我想使用NLTK来分析句子并将它们的块显示为一棵树。NLTK提供了tree.draw()方法来绘制树形图。下面的代码绘制了一个关于句子"the little yellow dog barked at the cat"的树形图:
import nltk
sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"), ("dog", "NN"), ("barked","VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
pattern = "NP: {<DT>?<JJ>*<NN>}"
NPChunker = nltk.RegexpParser(pattern)
result = NPChunker.parse(sentence)
result.draw()
结果是这棵树:

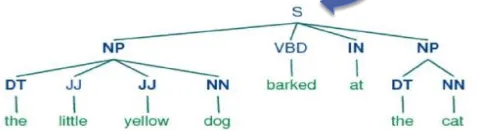
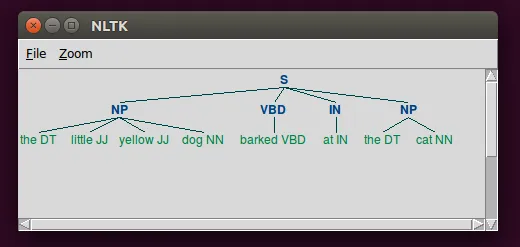
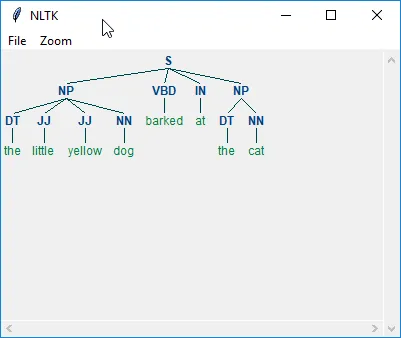{kind=link}
.draw()纯粹是展示,所以它不会改变解析结果太多=)只是为了再次确认,@raxer,这是你要问的吗? - alvasJJ。在第一张图片中,JJ与“黄色”处于同一层级。但在第二张图片中,“JJ”在“黄色”上方一层。我该如何像第二张图片那样显示它? - raxer