请问有人可以解释下DHT是如何工作的吗?
不用太深入,只讲基本概念即可。
好的,它们基本上是一个相当简单的想法。DHT提供类似于字典的接口,但节点分布在网络中。 DHT的诀窍在于通过对键进行哈希来找到存储特定键的节点,因此实际上您的哈希表桶现在是网络中独立的节点。
这提供了很多容错性和可靠性,并可能带来一些性能优势,但也引发了很多问题。例如,当节点离开网络时(通过故障或其他方式),会发生什么?当节点加入时,如何重新分配密钥以使负载大致平衡?考虑一下,如何均匀分配密钥?当节点加入时,如何避免重新哈希所有内容?(如果您增加桶的数量,必须在普通哈希表中执行此操作)。
解决其中某些问题的一个示例DHT是具有n个节点的逻辑环,每个节点负责1 / n的键空间。将节点添加到网络后,它会找到环中两个其他节点之间的位置,并负责其兄弟节点中的某些键。这种方法的美妙之处在于,环中的其他节点都不受影响;只有两个兄弟节点必须重新分配密钥。
例如,在一个三个节点的环中,第一个节点具有键0-10,第二个节点具有键11-20,第三个节点具有键21-30。如果第四个节点出现并将自己插入节点3和节点0之间(记住,它们在一个环中),则它可以负责3的键空间的一半,因此现在它处理26-30,而节点3处理21-25。
还有许多其他类似于此类的覆盖结构,使用基于内容的路由查找正确的节点以存储键。在环中定位键需要逐个节点搜索环(除非您保留本地查找表,在拥有数千个节点的DHT中存在问题),这是O(n)跳路由。其他结构 - 包括增强型环 - 保证O(log n)跳路由,并且有些声称以更多的维护成本来实现O(1)跳路由。
阅读维基百科页面,如果想要深入了解,请查看哈佛大学的这个课程页面,其中有一个相当全面的阅读列表。
DHTs提供与普通哈希表相同的用户接口(通过键查找值),但数据分布在任意数量的连接节点上。如果写更多,我基本上会重复维基百科的良好基础介绍 -
hash(x)/R得到的结果是34500。你仍然需要执行34500 % 3的操作。 - Pacerier去中心化:由于没有中央机构或协调,因此系统是去中心化的。
可扩展的:系统可以轻松扩展到数百万个节点。
容错的:DHT将数据存储在所有节点上进行复制。因此,即使一个节点离开网络,它也不应影响网络中的其他节点。
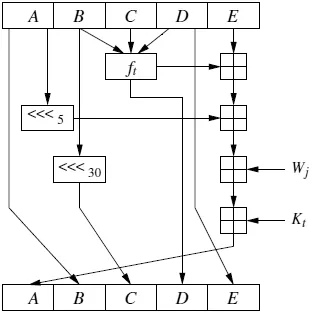
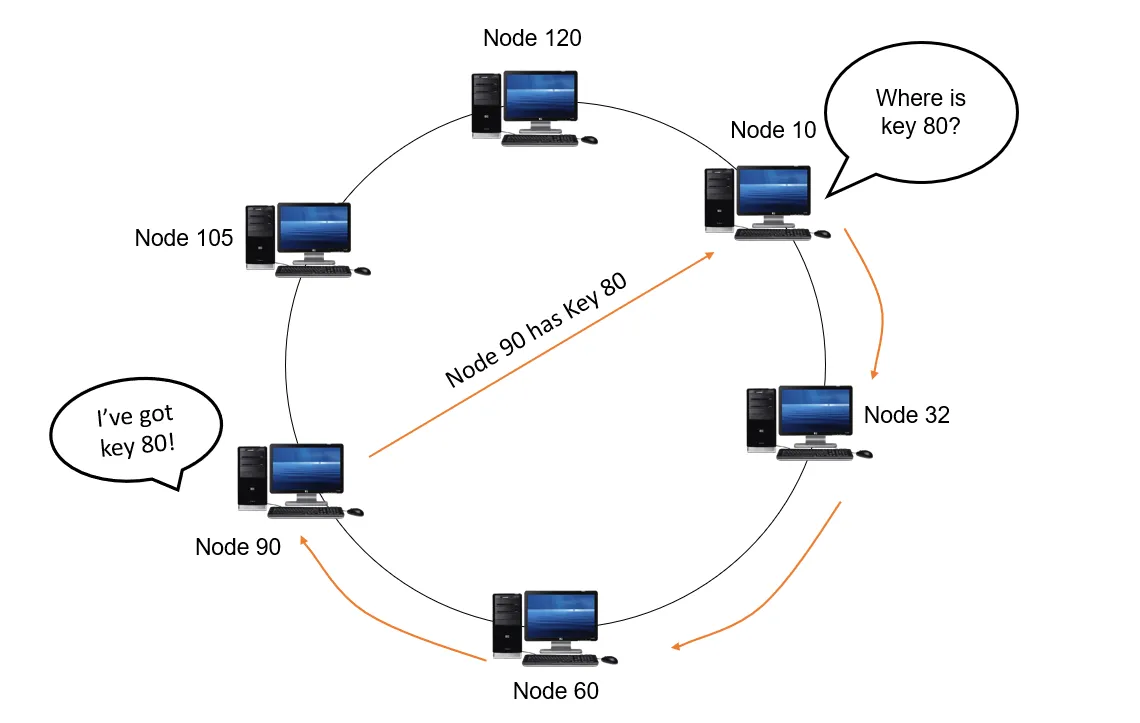
让我们看看像Chord这样的流行DHT协议中查找是如何进行的。考虑一个循环双向链表节点。每个节点都有指向其前面和后面节点的引用指针。紧接着该节点的下一个节点称为“后继节点”。而在该节点之前的节点称为“前驱节点”。
在DHT方面,每个节点都有k位的唯一节点ID,这些节点按其节点ID的增加顺序排列。假设这些节点按照称为标识符环的环形结构排列。对于每个节点,后继节点沿顺时针方向距离最短。对于大多数节点,这是其ID最接近但仍大于当前节点ID的节点。要找到适合特定密钥的节点,请先使用一致性哈希技术(如SHA-1)对密钥K和所有节点进行精确到k位的哈希。