一种懒惰而高效的T-SQL方法:
在我的情况下,一些表很大,因此脚本化数据是不切实际的。
另外,我们只需要迁移一个非常大的数据库的一小部分,所以我不想备份/恢复。
所以我选择了INSERT INTO / SELECT FROM,并使用information_schema等来生成代码。
步骤1:在新DB上创建表
对于要迁移到新数据库的每个表,在新数据库上创建该表。
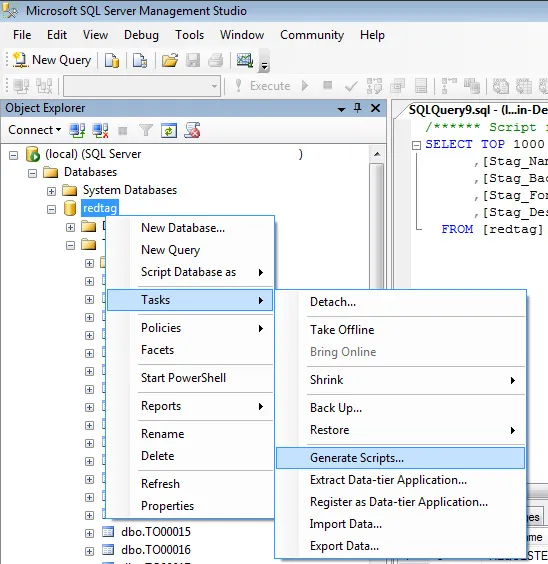
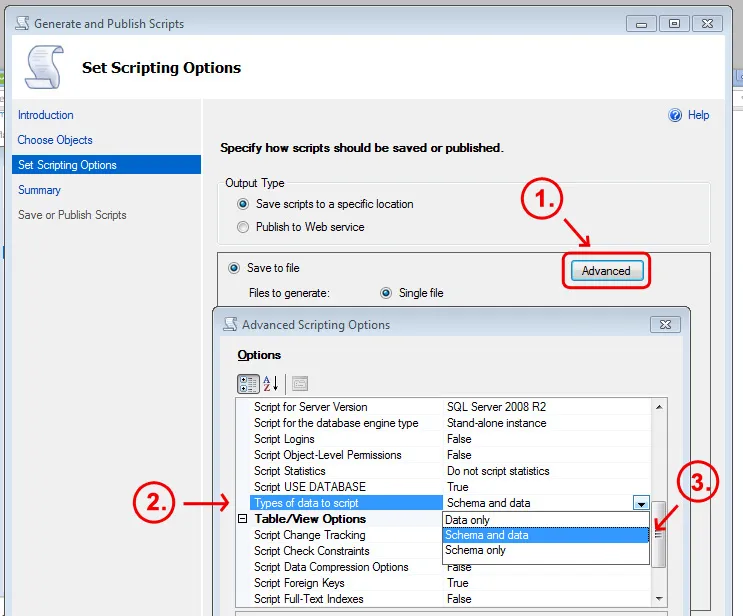
可以脚本化表,或使用SQL Compare、information_schema的动态sql等多种方式。dallin的答案展示了一种使用SSMS的方法(但一定要仅选择模式)。
步骤2:在目标DB上创建UDF以生成列列表
这只是用于生成代码的辅助函数。
USE [staging_edw]
GO
CREATE FUNCTION dbo.udf_get_column_list
(
@table_name varchar(8000)
)
RETURNS VARCHAR(8000)
AS
BEGIN
DECLARE @var VARCHAR(8000)
SELECT
@var = COALESCE(@var + ',', '', '') + c.COLUMN_NAME
FROM INFORMATION_SCHEMA.columns c
WHERE c.TABLE_SCHEMA + '.' + c.TABLE_NAME = @table_name
AND c.COLUMN_NAME NOT LIKE '%hash%'
RETURN @var
END
第三步:创建日志表
生成的代码将记录进度到此表中,以便您进行监控。但是您必须先创建此日志表。
USE staging_edw
GO
IF OBJECT_ID('dbo.tmp_sedw_migration_log') IS NULL
CREATE TABLE dbo.tmp_sedw_migration_log
(
step_number INT IDENTITY,
step VARCHAR(100),
start_time DATETIME
)
步骤4:生成迁移脚本
在这里,您将生成用于迁移数据的T-SQL。它只是为每个表生成INSERT INTO / SELECT FROM语句,并记录其进度。
此脚本实际上不会修改任何内容。它只输出一些代码,您可以在执行之前进行检查。
USE staging_edw
GO
DECLARE @n VARCHAR(100) = CHAR(13)+CHAR(10)
DECLARE @t VARCHAR(100) = CHAR(9)
DECLARE @2n VARCHAR(100) = @n + @n
DECLARE @2nt VARCHAR(100) = @n + @n + @t
DECLARE @nt VARCHAR(100) = @n + @t
DECLARE @n2t VARCHAR(100) = @n + @t + @t
DECLARE @2n2t VARCHAR(100) = @n + @n + @t + @t
DECLARE @3n VARCHAR(100) = @n + @n + @n
IF OBJECT_ID('tempdb..#identities') IS NOT NULL
DROP TABLE #identities;
SELECT
table_schema = s.name,
table_name = o.name
INTO #identities
FROM sys.objects o
JOIN sys.columns c on o.object_id = c.object_id
JOIN sys.schemas s ON s.schema_id = o.schema_id
WHERE 1=1
AND c.is_identity = 1
SELECT
@3n + '-- ' + t.TABLE_SCHEMA + '.' + t.TABLE_NAME,
@n + 'BEGIN TRY',
@2nt + IIF(i.table_schema IS NOT NULL, 'SET IDENTITY_INSERT staging_edw.' + t.TABLE_SCHEMA + '.' + t.TABLE_NAME + ' ON ', ''),
@2nt + 'TRUNCATE TABLE staging_edw.' + t.TABLE_SCHEMA + '.' + t.TABLE_NAME,
@2nt + 'INSERT INTO staging_edw.' + t.TABLE_SCHEMA + '.' + t.TABLE_NAME + ' WITH (TABLOCKX) ( ' + f.f + ' ) ',
@2nt + 'SELECT ' + f.f + + @nt + 'FROM staging.' + t.TABLE_SCHEMA + '.' + t.TABLE_NAME,
@2nt + IIF(i.table_schema IS NOT NULL, 'SET IDENTITY_INSERT staging_edw.' + t.TABLE_SCHEMA + '.' + t.TABLE_NAME + ' OFF ', ''),
@2nt + 'INSERT INTO dbo.tmp_sedw_migration_log ( step, start_time ) VALUES ( ''' + t.TABLE_SCHEMA + '.' + t.TABLE_NAME + ' inserted successfully'', GETDATE() );' ,
@2n + 'END TRY',
@2n + 'BEGIN CATCH',
@2nt + 'INSERT INTO dbo.tmp_sedw_migration_log ( step, start_time ) VALUES ( ''' + t.TABLE_SCHEMA + '.' + t.TABLE_NAME + ' FAILED'', GETDATE() );' ,
@2n + 'END CATCH'
FROM INFORMATION_SCHEMA.tables t
OUTER APPLY (SELECT f = staging_edw.dbo.udf_get_column_list(t.TABLE_SCHEMA + '.' + t.TABLE_NAME)) f
LEFT JOIN #identities i ON i.table_name = t.TABLE_NAME
AND i.table_schema = t.TABLE_SCHEMA
WHERE t.TABLE_TYPE = 'base table'
步骤5:运行代码
现在,您只需要将步骤4中的输出复制并粘贴到新的查询窗口中,然后运行即可。
注意事项
- 在步骤1中,我从列列表(在UDF中)中排除了哈希列,因为在我的情况下这些是计算列。