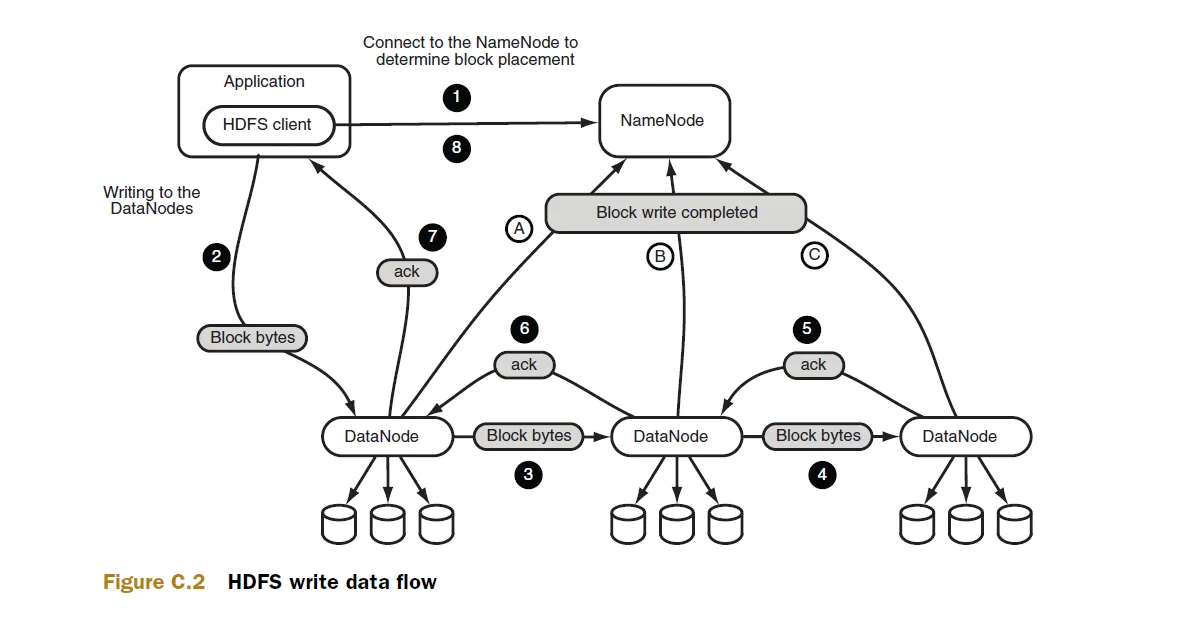
确认以下内容是否正确: 1. 按照我的理解,当我们将一个文件复制到HDFS时,该文件(假设其大小>64MB = HDFS块大小)会被分成多个块,并且每个块都会存储在不同的数据节点上。
文件内容在复制到HDFS时已经被分割成块,并且文件的拆分不会在运行map任务时发生。map任务只是按照这样的方式调度,使它们可以处理每个最大大小为64 MB的块,并且具有数据本地性(即map任务在包含数据/块的节点上运行)
如果文件被压缩(gzipped),也会进行文件拆分,但MR确保每个文件仅由一个mapper处理,即MR将收集在其他数据节点上的gzip文件的所有块并将其全部交给单个mapper。
如果我们定义isSplitable()返回false,则与上述相同的事情将发生,即一个正在运行的机器上的一个mapper将处理文件的所有块。 MR将从不同的数据节点读取文件的所有块,并将它们提供给单个mapper使用。