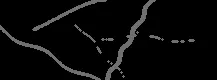
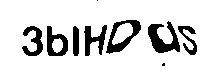
我试图清理上面的图片,使用了几种不同的方法,包括使用open cv,但是我会将原始图片腐蚀得太厉害,以至于字母的一些部分会变成缺失的,就像下面这样:

我真的不知道如何去除最后的对角线和修复S,我的代码到目前为止是:
import cv2
import matplotlib.pylab as plt
img = cv2.imread('/captcha_3blHDdS.png')
#make image gray
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#Blur
blur = cv2.GaussianBlur(gray,(5,5),0)
bilateral = cv2.bilateralFilter(gray,5,75,75)
#Thresholding
ret, thresh = cv2.threshold(bilateral,25,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
#Kernal
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
#other things
erosion = cv2.erode(thresh,kernel,iterations = 1)
closing = cv2.morphologyEx(erosion, cv2.MORPH_CLOSE, kernel, iterations = 1)
#Transform image
dist_transform = cv2.distanceTransform(closing,cv2.DIST_L2,5)
ret, sure_fg = cv2.threshold(dist_transform,0.02*dist_transform.max(),255,cv2.THRESH_BINARY)#,255,0)
#kernel_1
kernel_1 = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (1, 2))
dilation_1 = cv2.dilate(sure_fg,kernel_1,iterations = 2)
erosion_1 = cv2.erode(dilation_1,kernel_1,iterations = 3)
plt.imshow(erosion_1, 'gray')
 此外,这是一个包含图片的文件夹链接。
此外,这是一个包含图片的文件夹链接。