大家好,SO社区:
我是一名计算机科学专业的学生,目前正在进行一项实验,将MergeSort和InsertionSort相结合。我们知道,在特定阈值S下,InsertionSort的执行时间比MergeSort更快。因此,通过合并这两种排序算法,可以优化总运行时间。
然而,经过多次实验,使用1000个样本大小和不同大小的S,实验结果并没有每次给出明确的答案。下面是得到的较好结果的图片(请注意,有一半时间结果并不那么明确):
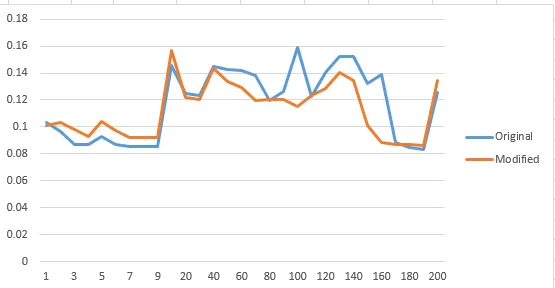
现在,我们尝试使用3500个样本大小来运行相同的算法代码:
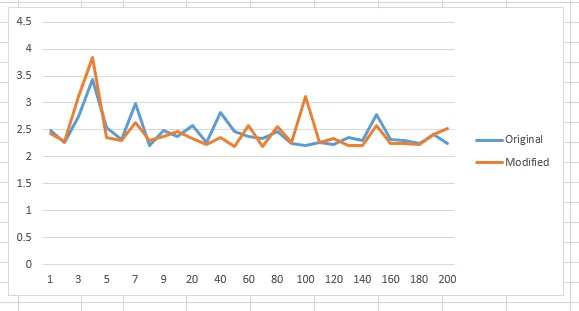
最后,我们尝试使用500,000个样本大小的相同算法代码(请注意,y轴以毫秒为单位):
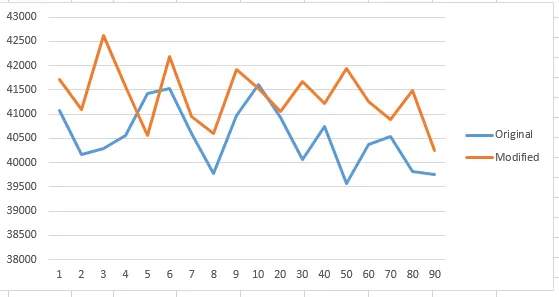
尽管从逻辑上讲,当S<=10时,混合MergeSort将更快,因为InsertionSort没有递归开销时间。然而,我的小实验结果表明不是这样的。
目前,这些是教给我的时间复杂度:
MergeSort:O(n log n)
InsertionSort:
- 最好情况:θ(n)
- 最坏情况:θ(n^2)
最后,我在网上找到了一个资源:https://cs.stackexchange.com/questions/68179/combining-merge-sort-and-insertion-sort它指出:
Hybrid MergeInsertionSort:
- 最好情况:θ(n + n log (n/x))
- 最坏情况:θ(nx + n log (n/x))
我想问一下,是否有CS社区的结果显示,在某个阈值S下,混合的MergeSort算法将比普通的MergeSort算法效果更好,并且为什么?
非常感谢SO社区,这可能是一个琐碎的问题,但它确实会澄清我目前对时间复杂度和其他方面的许多疑问。
注意:我正在使用Java来编写算法,并且运行时间可能会受到java存储数据的方式的影响。
Java代码:
public static int mergeSort2(int n, int m, int s, int[] arr){
int mid = (n+m)/2, right=0, left=0;
if(m-n<=s)
return insertSort(arr,n,m);
else
{
right = mergeSort2(n, mid,s, arr);
left = mergeSort2(mid+1,m,s, arr);
return right+left+merge(n,m,s,arr);
}
}
public static int insertSort(int[] arr, int n, int m){
int temp, comp=0;
for(int i=n+1; i<= m; i++){
for(int j=i; j>n; j--){
comp++;
comparison2++;
if(arr[j]<arr[j-1]){
temp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = temp;
}
else
break;
}
}
return comp;
}
public static void shiftArr(int start, int m, int[] arr){
for(int i=m; i>start; i--)
arr[i] = arr[i-1];
}
public static int merge(int n, int m, int s, int[] arr){
int comp=0;
if(m-n<=s)
return 0;
int mid = (n+m)/2;
int temp, i=n, j=mid+1;
while(i<=mid && j<=m)
{
comp++;
comparison2++;
if(arr[i] >= arr[j])
{
if(i==mid++&&j==m && (arr[i]==arr[j]))
break;
temp = arr[j];
shiftArr(i,j++,arr);
arr[i] = temp;
if(arr[i+1]==arr[i]){
i++;
}
}
i++;
}
return comp;
}