我编写了这个SOR求解器代码。不要过多关注算法的具体作用,这不是我们关心的重点。但为了完整起见,它可以解决一个线性方程组,取决于系统的条件。
我在一个病态的2097152行稀疏矩阵上运行它(它永远不会收敛),每行最多有7列非零元素。
简单来说,外部的do-while循环将执行10000次迭代(即我传递给它的max_iters值),中间的for循环将执行2097152次迭代,按照work_line分割成若干块,并在OpenMP线程之间进行划分。最内层的for循环将执行7次迭代,除了极少数情况(不到1%)外,它可能会少于7次。
在sol数组的值之间存在数据依赖关系。中间的for循环的每次迭代都会更新一个元素,但会读取数组中其他6个元素的值。由于SOR不是一个精确的算法,在读取时,它可能会在该位置上任意使用之前或当前的值(如果您熟悉求解器,这是一种Gauss-Siedel算法,在某些地方为了并行性而容忍Jacobi算法的行为)。
typedef struct{
size_t size;
unsigned int *col_buffer;
unsigned int *row_jumper;
real *elements;
} Mat;
int work_line;
// Assumes there are no null elements on main diagonal
unsigned int solve(const Mat* matrix, const real *rhs, real *sol, real sor_omega, unsigned int max_iters, real tolerance)
{
real *coefs = matrix->elements;
unsigned int *cols = matrix->col_buffer;
unsigned int *rows = matrix->row_jumper;
int size = matrix->size;
real compl_omega = 1.0 - sor_omega;
unsigned int count = 0;
bool done;
do {
done = true;
#pragma omp parallel shared(done)
{
bool tdone = true;
#pragma omp for nowait schedule(dynamic, work_line)
for(int i = 0; i < size; ++i) {
real new_val = rhs[i];
real diagonal;
real residual;
unsigned int end = rows[i+1];
for(int j = rows[i]; j < end; ++j) {
unsigned int col = cols[j];
if(col != i) {
real tmp;
#pragma omp atomic read
tmp = sol[col];
new_val -= coefs[j] * tmp;
} else {
diagonal = coefs[j];
}
}
residual = fabs(new_val - diagonal * sol[i]);
if(residual > tolerance) {
tdone = false;
}
new_val = sor_omega * new_val / diagonal + compl_omega * sol[i];
#pragma omp atomic write
sol[i] = new_val;
}
#pragma omp atomic update
done &= tdone;
}
} while(++count < max_iters && !done);
return count;
}
如您所见,在并行区域内没有锁定,因此根据他们经常教给我们的,这是一种100%并行的问题。但实际情况并非如此。
我所有的测试都在Intel(R)Xeon(R)CPU E5-2670 v2 @ 2.50GHz上运行,有2个处理器,每个有10个内核,启用了超线程技术,总共有40个逻辑内核。
在我的第一组运行中,work_line 固定为2048,线程数从1到40变化(总共40次运行)。这是每次运行的执行时间的图表(秒 x 线程数):
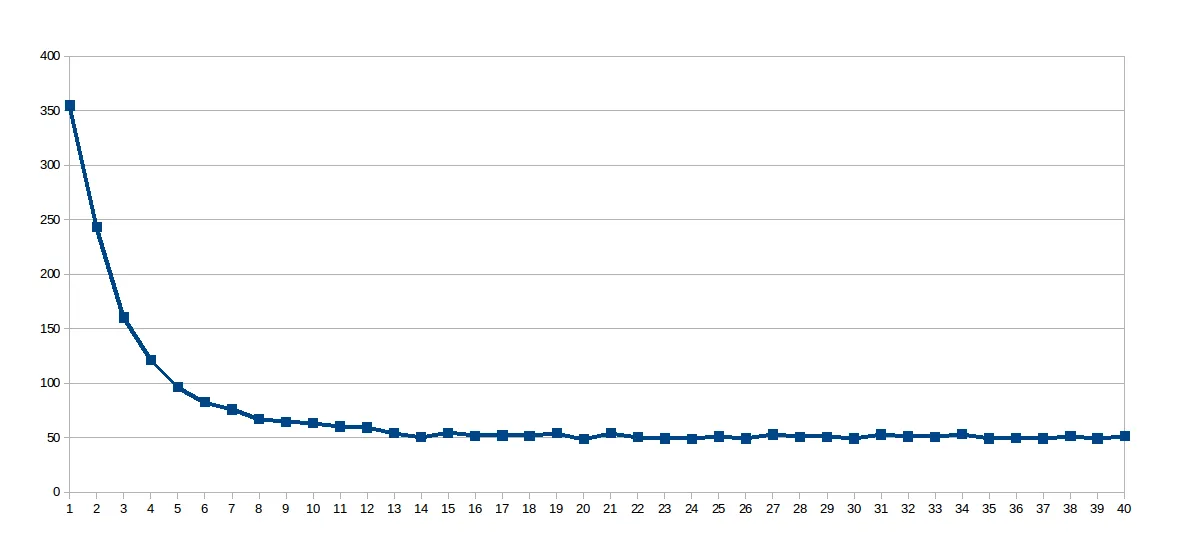
惊喜的是它呈现出对数曲线,因此我认为由于工作线程很大,共享缓存并未得到很好的利用,因此我查找了该虚拟文件 / sys / devices / system / cpu / cpu0 / cache / index0 / coherency_line_size ,它告诉我这个处理器的L1缓存将更新以64字节(数组sol 中的8个双精度数)为一组进行同步。因此我将 work_line 设置为8:
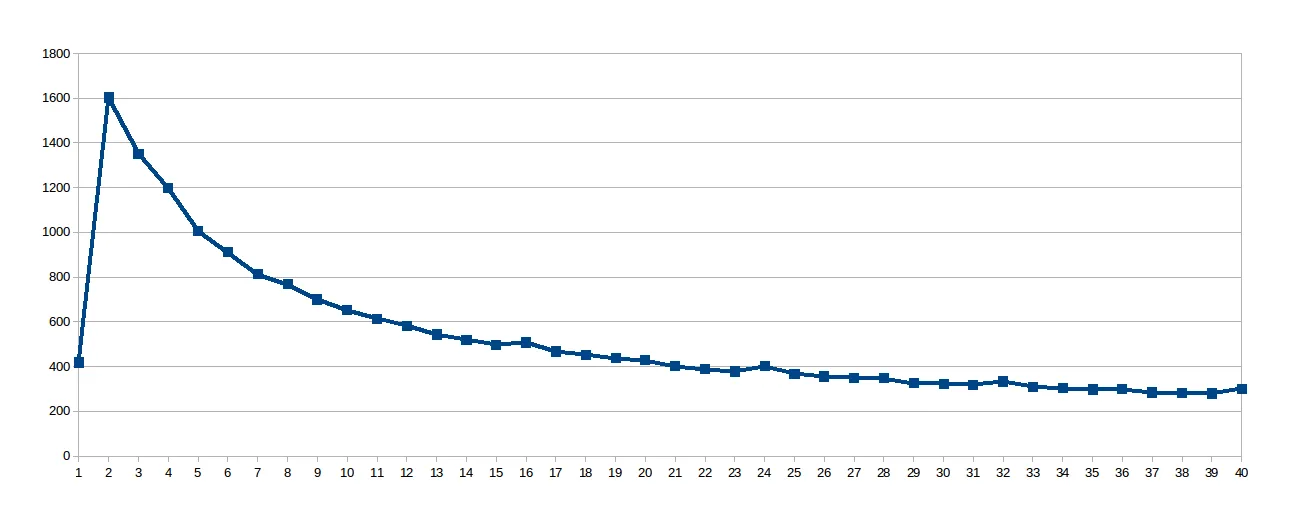
然后我认为8太低,无法避免NUMA停滞,并将 work_line 设置为16:
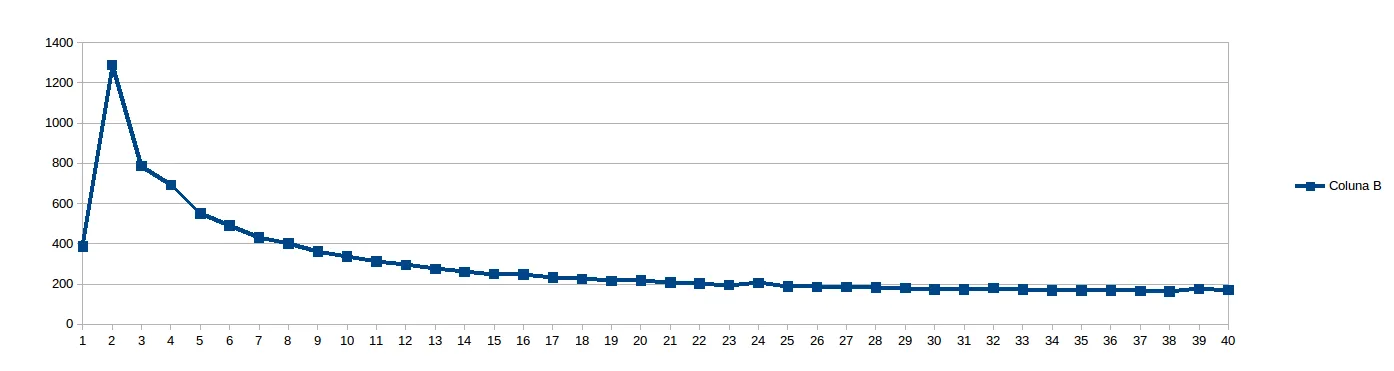
在运行上述内容时,我想到“我有什么权力预测哪个work_line是好的呢?让我们看看...”,并计划运行从8到2048的每个 work_line ,步长为8(即从1到256的缓存线的每个倍数)。以下是20和40个线程的结果(以中间的for循环的分裂大小为单位,平均分配给线程):
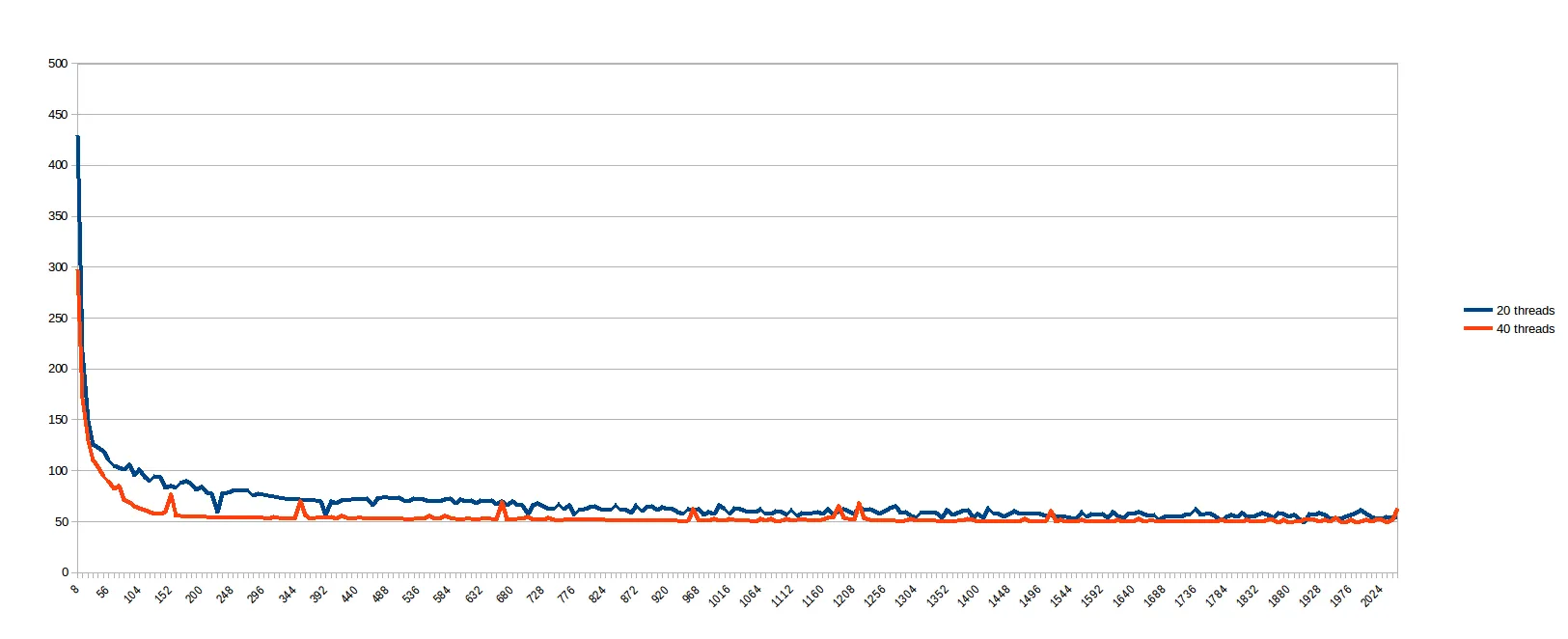
我认为具有较小work_line的情况会因缓存同步而受到严重影响,而较大的work_line在一定数量的线程之外不提供任何好处(我假设是因为内存通道是瓶颈)。很遗憾,一个似乎100%并行的问题在实际机器上呈现出如此糟糕的行为。因此,在被说服多核系统是一个非常出色的谎言之前,我首先问你:
如何使此代码按线性比例扩展到核心数?我缺少什么?是否有什么东西使它不像一开始看起来那么好?
更新
根据建议,我尝试使用static和dynamic调度,但是去除了sol数组上的原子读/写操作。供参考,蓝色和橙色线与上一个图表相同(只到 work_line = 248;)。黄色和绿色线是新的。就我所看到的,
和export OMP_NUM_THREADS=20`,你的代码将在一个节点上运行(即一个套接字)。 - Z bosonexport GOMP_CPU_AFFINITY="0-62:2"的简写。至于拓扑结构,核心编号由BIOS设置,Linux内核通过解析相应的MP ACPI表(MADT?虽然我不确定)来找到它。Bull的大多数双插槽Intel机器都将核心放在一个单独的包中按顺序编号。 - Hristo Iliev