使用Fetch API,我可以发起一个网络请求以获取大量二进制数据(例如超过500 MB),然后将响应转换为
接下来,我可以使用
一开始,似乎最好将数据作为
我已经准备了一个演示来尝试这两种方法之间的差异:https://blobvsab.vercel.app/。我正在使用这两种方法获取656 MB的二进制数据。
后两个快照是在我使用
现在,这就是直接获取
Blob或ArrayBuffer。接下来,我可以使用
worker.postMessage方法,让标准结构化克隆算法复制Blob到Web Worker,或将ArrayBuffer传输到工作线程上下文中(从而使其不再在主线程中可用)。一开始,似乎最好将数据作为
ArrayBuffer获取,因为Blob无法传输,因此需要复制。但是,Blob是不可变的,因此浏览器似乎没有将其存储在与页面关联的JS堆中,而是存储在专用的Blob存储空间中。因此,复制到工作线程上下文中的实际上只是一个引用。我已经准备了一个演示来尝试这两种方法之间的差异:https://blobvsab.vercel.app/。我正在使用这两种方法获取656 MB的二进制数据。
我在本地测试中观察到的有趣现象是,复制 Blob 的速度甚至比传输 ArrayBuffer 更快:
从主线程到工作线程的 Blob 复制时间:1.828125 毫秒
从主线程到工作线程的 ArrayBuffer 传输时间:3.393310546875 毫秒
这表明处理 Blob 实际上是相当便宜的一个强有力的指标。由于它们是不可变的,浏览器似乎聪明到将它们视为引用而不是将潜在的二进制数据链接到这些引用。
这是我在获取 Blob 时拍摄的堆内存快照:

postMessage将获取到的Blob复制到worker上下文后拍摄的。请注意,这两个堆中都不包括656 MB。后两个快照是在我使用
FileReader实际访问底层数据之后拍摄的,如预期的那样,堆增长了很多。现在,这就是直接获取
ArrayBuffer时发生的情况:
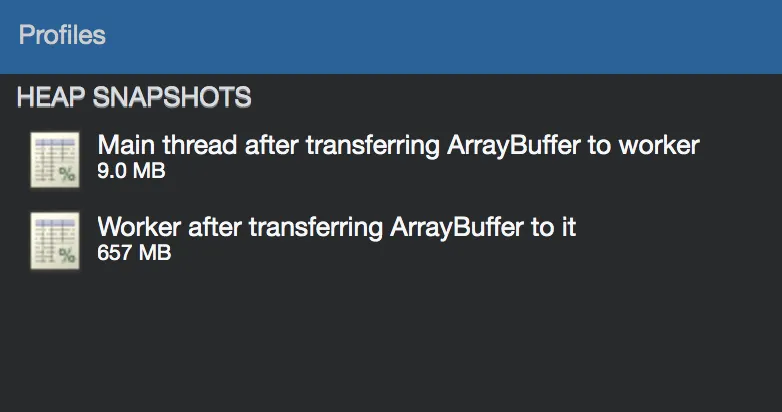
这里,由于二进制数据仅在工作线程中传输,因此主线程的堆很小,而工作线程的堆包含整个656 MB的数据,即使在读取此数据之前也是如此。
现在,在SO上查看What is the difference between an ArrayBuffer and a Blob?,可以看到两种结构之间存在许多基本差异,但我没有找到关于是否应该担心在执行上下文之间复制Blob还是ArrayBuffer固有优势的好参考。然而,我的实验表明,复制Blob可能实际上更快,因此我认为更可取。
每个浏览器供应商似乎都有自己的存储和处理 Blob 的方式。我找到了这份Chromium文档,它描述了所有 Blob 都从每个渲染器进程(即标签页上的页面)传输到浏览器进程,这样Chrome甚至可以将Blob卸载到辅助内存中。
是否有人对此有更多见解?如果我可以选择通过网络获取一些大型二进制数据并将其移动到Web Worker,那么我应该选择Blob还是ArrayBuffer?