我需要在SQL Server上制作一个数据透视表。
我有一个视图,返回以下结果:
我有一个视图,返回以下结果:
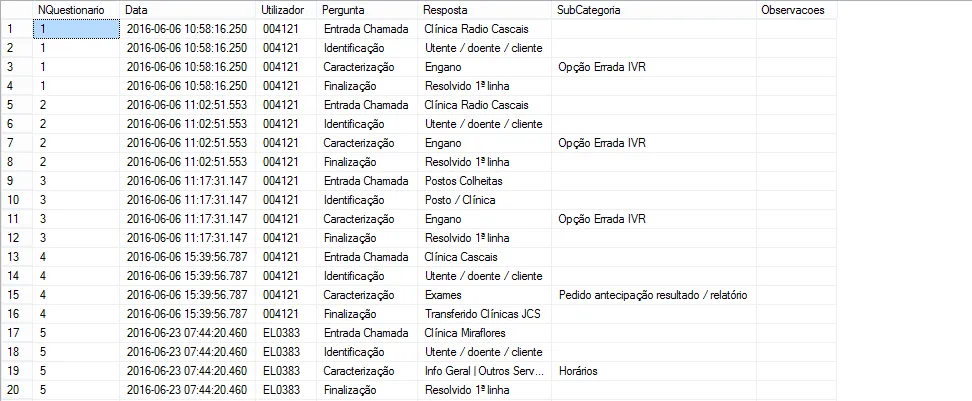

我做了这个查询:
DECLARE @cols AS NVARCHAR(MAX),
@cols2 AS NVARCHAR(MAX),
@query AS NVARCHAR(MAX)
select @cols = STUFF((SELECT distinct ',' + QUOTENAME(pergunta)
from [dbo].[VRespostas]
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'')
set @cols2 = '[NQuestionario],[Data],[Utilizador],' + @cols + ',[SubCategoria],[Observacoes]'
print @cols + ' '+ @cols2
set @query = 'SELECT ' + @cols2 + ' from
(
select *
from [dbo].[VRespostas]
) x
pivot
(
max(Resposta)
for Pergunta in (' + @cols + ')
) p '
execute(@query)
这个结果基本符合我的要求,但是对于任何ID它都给了我两行,而我只想要一行。
结果如下:
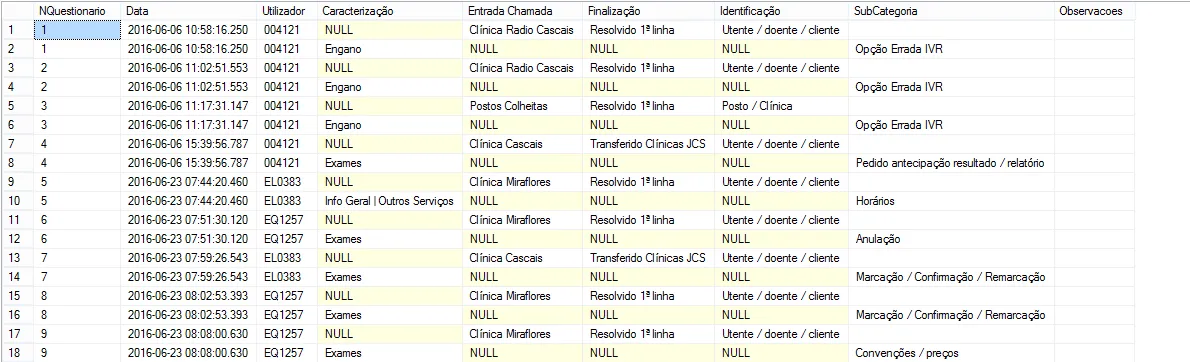
我做错了什么?
你能帮助我吗?
附言:抱歉我的英语不好。 :)
.. ((SELECT distinct ', max(case pergunta when ''' + pergunta + ''' then pergunta end) as ' + QUOTENAME(pergunta) ...而不是使用 pivot,所有的聚合都可以在单个步骤中一致地完成。 - Serg