我已查看了它们的文档。
这个问题是由J.F.在这里发表评论引起的:检索subprocess.call()的输出 关于使用
注意,不要在此函数中使用
Python 2.7
请勿在此函数中使用
Python 2.6没有这样的警告。
另外,
这个问题是由J.F.在这里发表评论引起的:检索subprocess.call()的输出 关于使用
PIPE进行subprocess.call(),当前Python文档中subprocess.call()表示如下:注意,不要在此函数中使用
stdout=PIPE或stderr=PIPE。如果子进程生成足够的输出填充操作系统管道缓冲区,则该子进程将阻塞,因为管道未被读取。Python 2.7
subprocess.call():请勿在此函数中使用
stdout=PIPE或stderr=PIPE,因为这可能会导致子进程输出量死锁。当需要使用管道时,请使用带有communicate()方法的Popen。Python 2.6没有这样的警告。
另外,
subprocess.call()和subprocess.check_call()似乎没有访问其输出的方法,除了使用stdout=PIPE与communicate()一起使用。
https://docs.python.org/2.6/library/subprocess.html#convenience-functions
请注意,如果您想将数据发送到进程的标准输入(stdin),则需要使用stdin=PIPE创建Popen对象。类似地,要在结果元组中获得除None以外的任何内容,您还需要同时提供stdout=PIPE和/或stderr=PIPE。https://docs.python.org/2.6/library/subprocess.html#subprocess.Popen.communicate
< p> subprocess.call() 和 subprocess.Popen() 之间的区别是什么,使得对于 subprocess.call()来说, PIPE 不够安全?
更具体地说:为什么 subprocess.call()会出现“基于子进程输出量的死锁”,而 Popen()则不会?
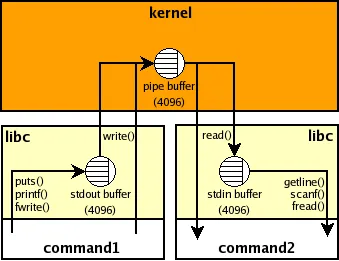
//开头呢? - chepner#,不同于C++、PHP和JavaScript。 - Damian Yerrick