我正在尝试使用Keras从数据集中预测价格值。我正在按照这个教程https://keras.io/examples/structured_data/structured_data_classification_from_scratch/进行操作,但当我到达模型拟合部分时,我得到了一个巨大的负损失和非常小的准确率。
我做错了什么?:(
编辑:我认为教程中的编码器函数正在规范化数据,但实际上并不是。你们知道其他更好的教程吗?损失问题已解决!(由于标准化导致)
Epoch 1/50
1607/1607 [==============================] - ETA: 0s - loss: -117944.7500 - accuracy: 3.8897e-05
2022-05-22 11:14:28.922065: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
1607/1607 [==============================] - 15s 10ms/step - loss: -117944.7500 - accuracy: 3.8897e-05 - val_loss: -123246.0547 - val_accuracy: 7.7791e-05
Epoch 2/50
1607/1607 [==============================] - 15s 9ms/step - loss: -117944.7734 - accuracy: 3.8897e-05 - val_loss: -123246.0547 - val_accuracy: 7.7791e-05
Epoch 3/50
1607/1607 [==============================] - 15s 10ms/step - loss: -117939.4844 - accuracy: 3.8897e-05 - val_loss: -123245.9922 - val_accuracy: 7.7791e-05
Epoch 4/50
1607/1607 [==============================] - 16s 10ms/step - loss: -117944.0859 - accuracy: 3.8897e-05 - val_loss: -123245.9844 - val_accuracy: 7.7791e-05
Epoch 5/50
1607/1607 [==============================] - 15s 10ms/step - loss: -117944.7422 - accuracy: 3.8897e-05 - val_loss: -123246.0547 - val_accuracy: 7.7791e-05
Epoch 6/50
1607/1607 [==============================] - 15s 10ms/step - loss: -117944.8203 - accuracy: 3.8897e-05 - val_loss: -123245.9766 - val_accuracy: 7.7791e-05
Epoch 7/50
1607/1607 [==============================] - 15s 10ms/step - loss: -117944.8047 - accuracy: 3.8897e-05 - val_loss: -123246.0234 - val_accuracy: 7.7791e-05
Epoch 8/50
1607/1607 [==============================] - 15s 10ms/step - loss: -117944.7578 - accuracy: 3.8897e-05 - val_loss: -123245.9766 - val_accuracy: 7.7791e-05
Epoch 9/50
这是我的图表, 就代码而言,它看起来像例子中的那个,但经过了改编:
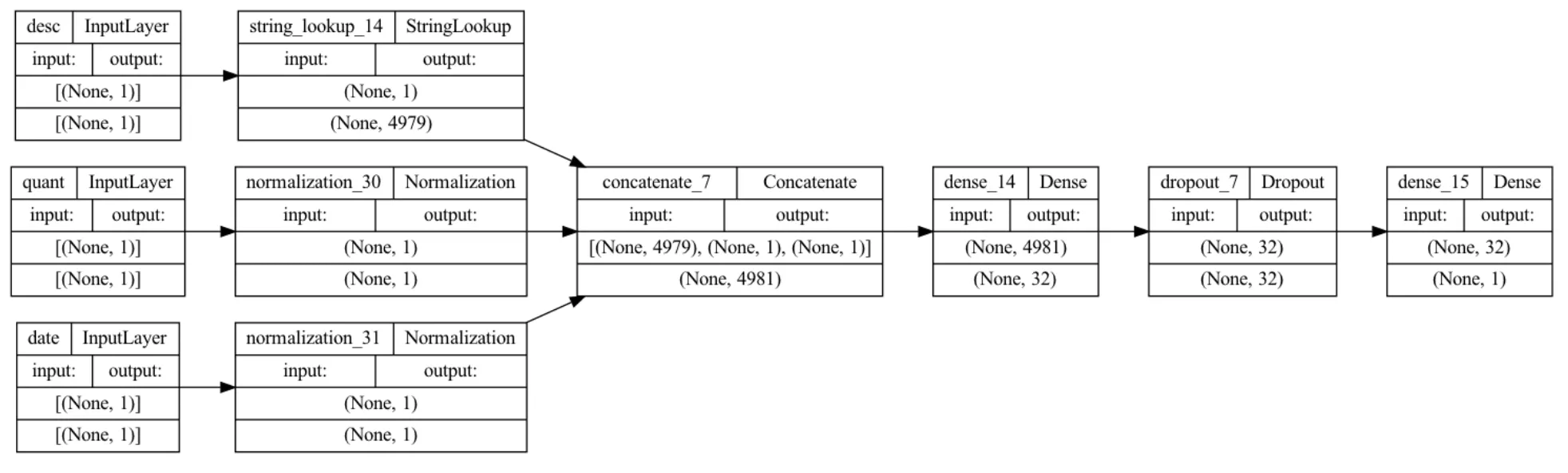{kind=link}
# Categorical feature encoded as string
desc = keras.Input(shape=(1,), name="desc", dtype="string")
# Numerical features
date = keras.Input(shape=(1,), name="date")
quant = keras.Input(shape=(1,), name="quant")
all_inputs = [
desc,
quant,
date,
]
# String categorical features
desc_encoded = encode_categorical_feature(desc, "desc", train_ds)
# Numerical features
quant_encoded = encode_numerical_feature(quant, "quant", train_ds)
date_encoded = encode_numerical_feature(date, "date", train_ds)
all_features = layers.concatenate(
[
desc_encoded,
quant_encoded,
date_encoded,
]
)
x = layers.Dense(32, activation="sigmoid")(all_features)
x = layers.Dropout(0.5)(x)
output = layers.Dense(1, activation="relu")(x)
model = keras.Model(all_inputs, output)
model.compile("adam", "binary_crossentropy", metrics=["accuracy"])
数据集如下所示:
date desc quant price
0 20140101.0 CARBONATO DE DIMETILO 999.00 1428.57
1 20140101.0 HIDROQUINONA 137.00 1314.82
2 20140101.0 1,5 PENTANODIOL TECN. 495.00 2811.60
3 20140101.0 SOSA CAUSTICA LIQUIDA 50% 567160.61 113109.14
4 20140101.0 BOROHIDRURO SODICO 6.24 299.27
我正在将日期从YYYY-MM-DD转换为数字,使用以下代码:
dataset['date'] = pd.to_datetime(dataset["date"]).dt.strftime("%Y%m%d").astype('float64')
我做错了什么?:(
编辑:我认为教程中的编码器函数正在规范化数据,但实际上并不是。你们知道其他更好的教程吗?损失问题已解决!(由于标准化导致)
binary_crossentropy更改为类似于mse的东西,要么将最后一层的relu更改为sigmoid。 - Kaveh