我有一个如下所示的表格,存储在字典中:
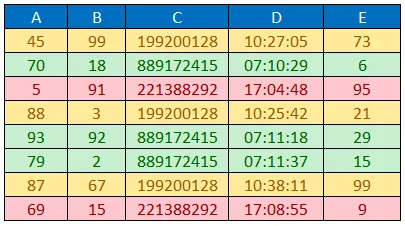
d = {
'A': ['45', '70', '5', '88', '93', '79', '87', '69'],
'B': ['99', '18', '91', '3', '92', '2', '67', '15'],
'C': ['199200128', '889172415', '221388292', '199200128', '889172415', '889172415', '199200128', '221388292'],
'D': ['10:27:05', '07:10:29', '17:04:48', '10:25:42', '07:11:18', '07:11:37', '10:38:11', '17:08:55'],
'E': ['73', '6', '95', '21', '29', '15', '99', '9']
}
我想按照从低到高的小时数对字典进行排序,并根据下图中列C中相同值对应的列A、B和E求和(A、B和E的总和以红色表示):
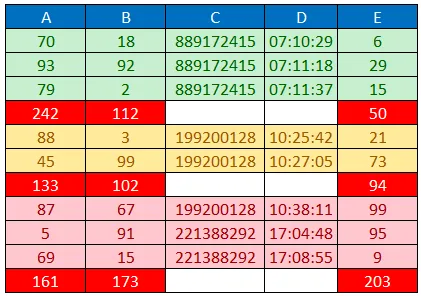
然后,生成的字典将如下所示:
{
'A': ['70', '93', '79', '242', '88', '45', '133', '87', '5', '69', '161'],
'B': ['18', '92', '2', '112', '3', '99', '102', '67', '91', '15', '173'],
'C': ['889172415', '889172415', '889172415', '', '199200128', '199200128', '', '199200128', '221388292', '221388292', ''],
'D': ['07:10:29', '07:11:18', '07:11:37', '', '10:25:42', '10:27:05', '', '10:38:11', '17:04:48', '17:08:55', ''],
'E': ['6', '29', '15', '50', '21', '73', '94', '99', '95', '9', '203']
}
我目前尝试使用这段代码对输入的字典进行排序,但似乎对我无效。
>>> sorted(d.items(), key=lambda e: e[1][4])
[
('D', ['10:27:05', '07:10:29', '17:04:48', '10:25:42', '07:11:18', '07:11:37', '10:38:11', '17:08:55']),
('E', ['73', '6', '95', '21', '29', '15', '99', '9']),
('C', ['199200128', '889172415', '221388292', '199200128', '889172415', '889172415', '199200128', '221388292']),
('B', ['99', '18', '91', '3', '92', '2', '67', '15']),
('A', ['45', '70', '5', '88', '93', '79', '87', '69'])
]
>>>
请问有人能给我提供帮助吗?感谢。
pd.DataFrame.from_dict(dictionary)时,它会生成一个带有索引的列,而在排序时,该列未排序(data.to_dict())。是否有一种方法可以避免生成该索引列,因为我发现如果有了这个额外的列,想要求和所需的值就更加复杂了。 - Ger Casorient = 'columns'参数。 - s3nh