假设我有一个数据框,存储在名为coordinates的变量中,前几行如下所示:
如您所见,这些数据是地理空间数据(具有纬度和经度),每一行还有一个附加值business_rating,对应该行中latlng位置上的业务评分。我想要对数据进行聚类,将附近且评分相似的业务分配到同一群集中。本质上来说,我需要一个地理空间聚类,另外要求聚类必须考虑评分列。
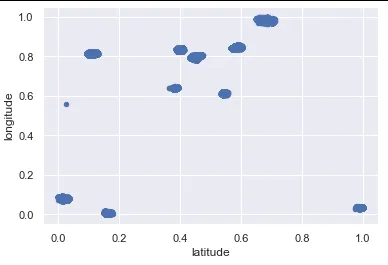
我已经在下方运行了一个简单的DBSCAN,但是当我绘制出聚类的结果时,它似乎没有正确地实现我的需求。
business_lat business_lng business_rating
0 19.111841 72.910729 5.
1 19.111342 72.908387 5.
2 19.111342 72.908387 4.
3 19.137815 72.914085 5.
4 19.119677 72.905081 2.
5 19.119677 72.905081 2.
. . .
. . .
. . .
如您所见,这些数据是地理空间数据(具有纬度和经度),每一行还有一个附加值business_rating,对应该行中latlng位置上的业务评分。我想要对数据进行聚类,将附近且评分相似的业务分配到同一群集中。本质上来说,我需要一个地理空间聚类,另外要求聚类必须考虑评分列。
我已经在下方运行了一个简单的DBSCAN,但是当我绘制出聚类的结果时,它似乎没有正确地实现我的需求。
from sklearn.cluster import DBSCAN
import numpy as np
db = DBSCAN(eps=2/6371., min_samples=5, algorithm='ball_tree', metric='haversine').fit(np.radians(coordinates))
我应该尝试调整DBSCAN的参数,对数据进行一些附加处理,还是完全采用其他方法?