一种可能性,也许有点天真,是在步骤中引入睡眠。为此,您需要知道可以同时运行的 ParDo 实例的最大数量。如果 autoscalingAlgorithm 设置为 NONE,则可以从 numWorkers 和 workerMachineType(DataflowPipelineOptions)获取该值。准确地说,有效速率将被总线程数除以: desired_rate/(num_workers*num_threads(per worker))。睡眠时间将是该有效速率的倒数:
Integer desired_rate = 1;
if (options.getNumWorkers() == 0) { num_workers = 1; }
else { num_workers = options.getNumWorkers(); }
if (options.getWorkerMachineType() != null) {
machine_type = options.getWorkerMachineType();
num_threads = Integer.parseInt(machine_type.substring(machine_type.lastIndexOf("-") + 1));
}
else { num_threads = 1; }
Double sleep_time = (double)(num_workers * num_threads) / (double)(desired_rate);
然后你可以在限制的函数内使用 TimeUnit.SECONDS.sleep(sleep_time.intValue()); 或等效的方法。在我的例子中,我想从公共文件中读取,解析出空行,并以最大1 QPS的速率调用自然语言处理API(我之前将desired_rate初始化为1):
p
.apply("Read Lines", TextIO.read().from("gs://apache-beam-samples/shakespeare/kinglear.txt"))
.apply("Omit Empty Lines", ParDo.of(new OmitEmptyLines()))
.apply("NLP requests", ParDo.of(new ThrottledFn()))
.apply("Write Lines", TextIO.write().to(options.getOutput()));
速率受限的Fn是
ThrottledFn,请注意
sleep函数:
static class ThrottledFn extends DoFn<String, String> {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
try (LanguageServiceClient language = LanguageServiceClient.create()) {
String text = c.element();
Document doc = Document.newBuilder()
.setContent(text).setType(Type.PLAIN_TEXT).build();
Sentiment sentiment = language.analyzeSentiment(doc).getDocumentSentiment();
String nlp_results = String.format("Sentiment: score %s, magnitude %s", sentiment.getScore(), sentiment.getMagnitude());
TimeUnit.SECONDS.sleep(sleep_time.intValue());
Log.info(nlp_results);
c.output(nlp_results);
}
}
}
使用此方法,如下图所示,我可以获得1个元素/秒的速率,并避免在使用多个工作者时达到配额限制,即使请求不是真正分散的(您可能会同时收到8个请求,然后休眠8秒等)。这只是一个测试,可能更好的实现方式是使用Guava的
rateLimiter。
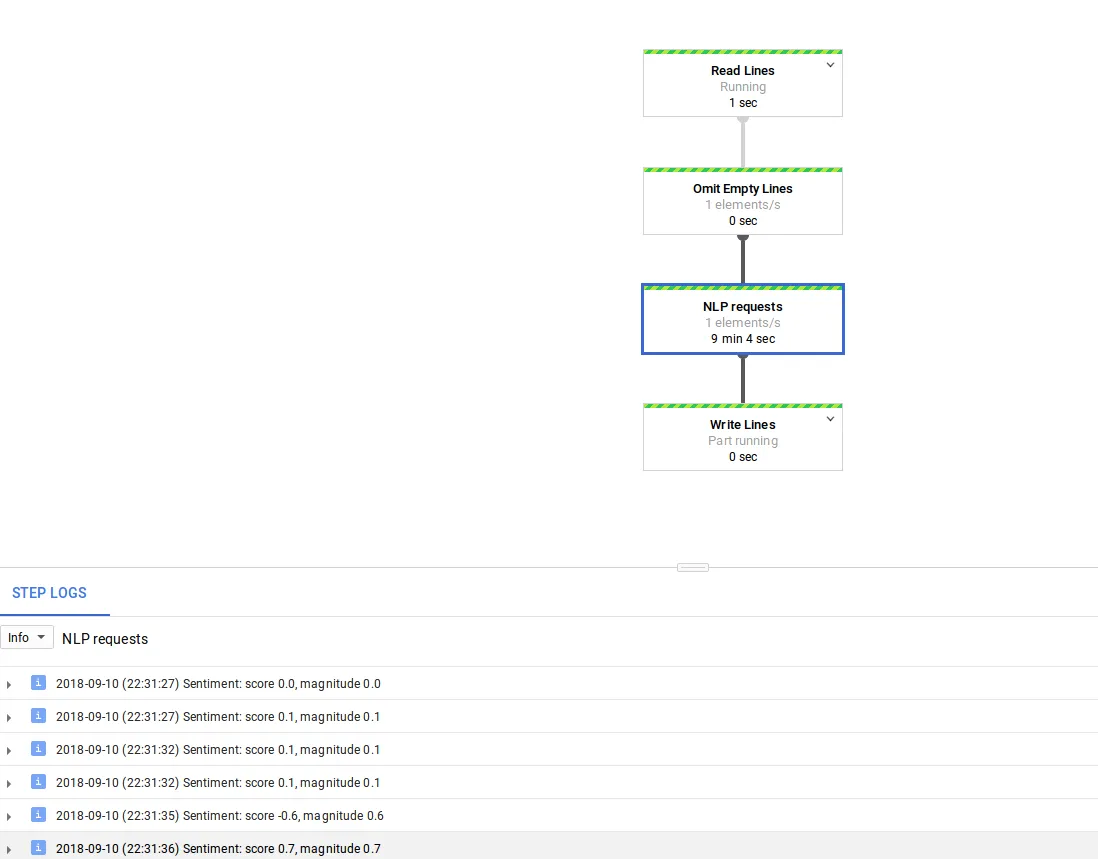
如果管道正在使用自动缩放(
THROUGHPUT_BASED),则会更加复杂,应该更新工作人员的数量(例如,Stackdriver Monitoring 具有
job/current_num_vcpus 指标)。其他一般考虑因素包括使用虚拟 GroupByKey 控制并行 ParDo 数量或使用 splitIntoBundles 分割源等。我希望看到是否有其他更好的解决方案。