假设我们有以下数据。
set.seed(123)
dat <- data.frame(var1=c(10,35,13,19,15,20,19), id=c(1,1,2,2,2,3,4))
(sampledIDs <- sample(min(dat$id):max(dat$id), size=3, replace=TRUE))
> [1] 2 4 2
sampledIDs是从dat$id中进行(带替换)抽样的id向量。
我需要能够在更多变量的大型数据集上使用的结果代码:
var1 id
13 2
19 2
15 2
19 4
13 2
19 2
15 2
代码dat[which(dat$id%in%sampledIDs),]不能给我想要的结果,因为这个代码的结果是:
var1 id
13 2
19 2
15 2
19 4
在这个数据中,仅当主体为dat$id==2时,其出现次数为一次(我知道结果是什么,但不知道如何获得我想要的结果)。请问有人能帮忙吗?
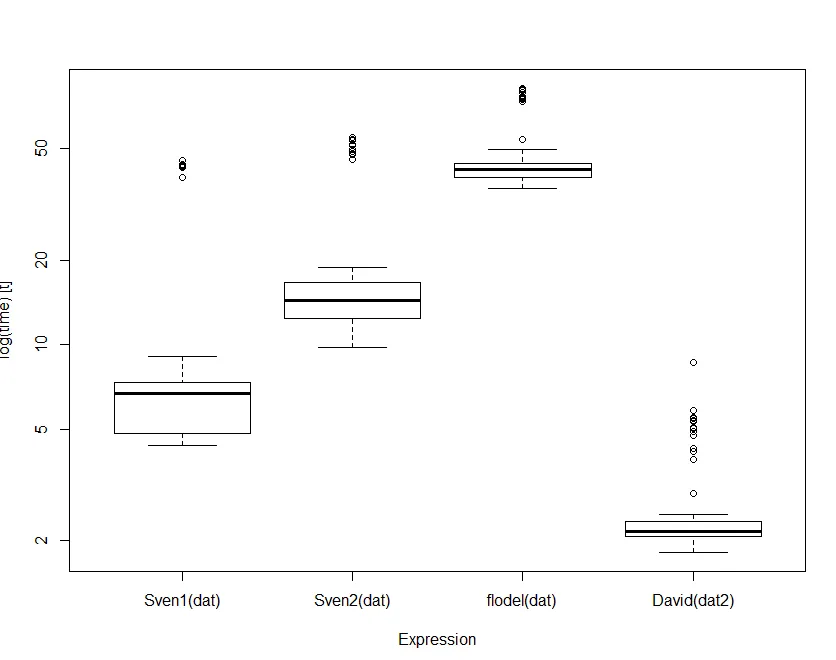
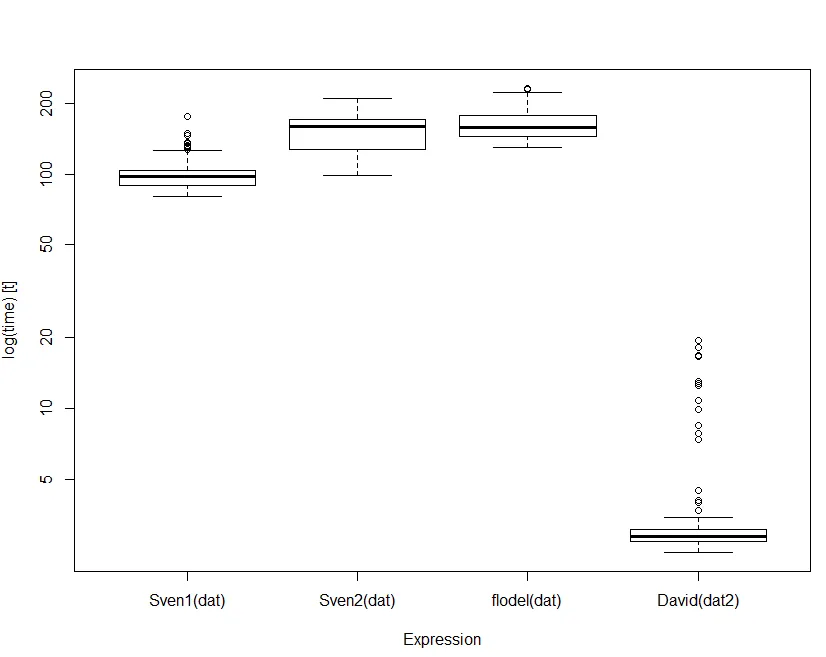
编辑:感谢答案,以下是所有答案的运行时间(对于那些感兴趣的人):
test replications elapsed relative user.self
3 dat[unlist(lapply(sampledIDs, function(x) which(x == dat$id))), ] 1000 0.67 1.000 0.64
1 dat[which(sapply(sampledIDs, "==", dat$id), arr.ind = TRUE)[, 1], ] 1000 0.67 1.000 0.67
2 do.call(rbind, split(dat, dat$id)[as.character(sampledIDs)]) 1000 1.83 2.731 1.83
4 setkey(setDT(dat), id)[J(sampledIDs)] 1000 1.33 1.985 1.33