我发现在Python 3.4中,有几个不同的多进程/线程库可以使用:multiprocessing vs threading vs asyncio。
但是我不知道应该使用哪一个或者哪一个是“推荐的”。它们是否做相同的事情,还是不同的?如果是这样的话,每个库用于什么?我想编写一个在我的计算机上利用多核的程序,但是我不知道应该学习哪个库。
我发现在Python 3.4中,有几个不同的多进程/线程库可以使用:multiprocessing vs threading vs asyncio。
但是我不知道应该使用哪一个或者哪一个是“推荐的”。它们是否做相同的事情,还是不同的?如果是这样的话,每个库用于什么?我想编写一个在我的计算机上利用多核的程序,但是我不知道应该学习哪个库。
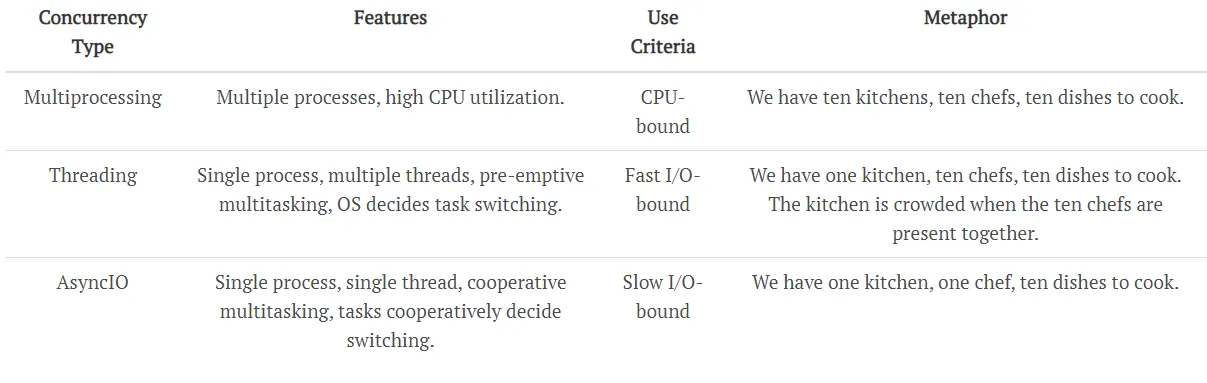
我们已经讨论了最常见的并发形式。但问题仍然存在 - 何时应该选择哪种形式?这真的取决于使用情况。根据我的经验(和阅读),我倾向于遵循这个伪代码:
if io_bound:
if io_very_slow:
print("Use Asyncio")
else:
print("Use Threads")
else:
print("Multi Processing")
- CPU Bound => 多进程处理
- I/O Bound, 快速 I/O, 连接数有限 => 多线程处理
- I/O Bound, 慢速 I/O, 连接数很多 => Asyncio 处理
[注]:
asyncio 事件循环(使用 uvloop 可以使 asyncio 的速度提升 2-4 倍)。[更新(2019)]:
asyncio。 request库不是一个可等待的方法,您可以使用aiohttp库或async-request等库代替。请注意,不要改变原来的意思。 - Benyamin Jafarimultiprocessing 可能比threading更受欢迎的原因。但并非每个问题都可以有效地分成[几乎独立的]部分,因此可能需要进行大量的进程间通信。因此,multiprocessing在一般情况下可能不如threading受欢迎。
asyncio(这种技术不仅在Python中可用,其他语言和/或框架也有,例如Boost.ASIO)是一种有效处理许多同时来源的I/O操作而无需并行代码执行的方法。因此,它只是一个特定任务的解决方案(确实是一个很好的解决方案!),而不是针对并行处理的一般性解决方案。在 multiprocessing 中,您可以利用多个CPU来分配计算任务。由于每个CPU都可以并行运行,因此您实际上可以同时运行多个任务。您需要使用multiprocessing来处理CPU-bound任务。例如,尝试计算巨大列表中所有元素的总和。如果您的计算机有8个内核,您可以将该列表“切分”成8个较小的列表,并在不同的核心上分别计算每个列表的总和,然后将这些数字相加即可。通过这样做,您将获得近8倍的加速效果。
在(multi)线程中,您不需要多个CPU。想象一个向网络发送大量HTTP请求的程序。如果使用单线程程序,则会在每个请求处停止执行(阻塞),等待响应,然后在收到响应后继续执行。问题在于,当等待一些外部服务器完成任务时,您的CPU实际上并没有做任何有用的工作,而它实际上可以在此期间进行一些有用的工作! 解决方法是使用线程-您可以创建许多线程,每个线程负责从Web请求某些内容。线程的好处在于,即使它们在一个CPU上运行,CPU也会不时地“冻结”一个线程的执行并跳转到执行另一个线程(这称为上下文切换,并且在非确定性间隔中不断发生)。因此,如果您的任务是I/O bound(即输入/输出受限),请使用线程。 asyncio 本质上就是线程,只不过不是CPU而是您作为程序员(或实际上是您的应用程序)决定何时以及在哪里进行上下文切换。在Python中,您使用await关键字来暂停协程的执行(使用async关键字定义)。async中开发者控制上下文切换,而在threading中操作系统控制上下文切换的方式。 - Arkyo因此,基本上除非您遇到IO/CPU问题,否则请坚持使用线程。它是IO密集型的吗?------------>使用
asyncio它是CPU密集型的吗?---------->使用
multiprocessing否则?---------------------------->使用
threading
asyncio来管理组合所有3种并发形式,并且如果需要,稍后可以轻松切换。
许多首次接触Python并发的开发人员最终会使用processing.Process和threading.Thread。然而,这些是低级API,已经通过concurrent.futures模块提供的高级API合并在一起。此外,生成进程和线程会产生开销,例如需要更多内存,这是一个我下面展示的示例所遇到的问题。在一定程度上,concurrent.futures会为您管理这个问题,因此您不能像生成几个进程并且每次完成后只重复使用这些进程那样轻易地生成一千个进程并使您的计算机崩溃。
这些高级API是通过concurrent.futures.Executor提供的,随后由concurrent.futures.ProcessPoolExecutor和concurrent.futures.ThreadPoolExecutor实现。在大多数情况下,应该使用这些而不是multiprocessing.Process和threading.Thread,因为当您使用concurrent.futures时,从一个API切换到另一个API更容易,并且您不必学习每个API的详细差异。
由于它们共享统一的接口,因此您还会发现使用multiprocessing或threading的代码通常会使用concurrent.futures。 asyncio也不例外,可以通过以下代码使用:
import asyncio
from concurrent.futures import Executor
from functools import partial
from typing import Any, Callable, Optional, TypeVar
T = TypeVar("T")
async def run_in_executor(
executor: Optional[Executor],
func: Callable[..., T],
/,
*args: Any,
**kwargs: Any,
) -> T:
"""
Run `func(*args, **kwargs)` asynchronously, using an executor.
If the executor is None, use the default ThreadPoolExecutor.
"""
return await asyncio.get_running_loop().run_in_executor(
executor,
partial(func, *args, **kwargs),
)
# Example usage for running `print` in a thread.
async def main():
await run_in_executor(None, print, "O" * 100_000)
asyncio.run(main())
threading和asyncio是非常常见的,以至于在Python 3.9中,他们添加了asyncio.to_thread(func,*args,**kwargs)来缩短默认ThreadPoolExecutor的长度。
有。对于asyncio,最大的缺点是异步函数与同步函数不同。这可能会让asyncio的新用户遇到很多问题,并导致需要做很多重新工作,如果你一开始没有考虑使用asyncio进行编程。
另一个缺点是你的代码用户也将被迫使用asyncio。所有这些必要的重新工作通常会让第一次使用asyncio的用户感到非常不愉快。
有。类似于使用concurrent.futures相对于threading.Thread和multiprocessing.Process具有统一接口的优势,这种方法可以被视为从执行程序到异步函数的进一步抽象。你可以从使用asyncio开始,如果后来发现你需要部分使用threading或multiprocessing,你可以使用asyncio.to_thread或run_in_executor. 同样,你可能会发现已经存在一个异步版本的你正在尝试使用线程运行的东西,因此你可以轻松地停止使用threading并改用asyncio。
有...也有没有。最终取决于任务。在某些情况下,它可能不会有所帮助(尽管它可能不会有害),而在其他情况下,它可能会有很大的帮助。本答案的其余部分提供了一些关于使用asyncio运行Executor的原因的解释。
asyncio本质上提供了更多的控制并发性的代价是需要更多地掌控并发性。如果您想同时运行一些使用ThreadPoolExecutor的代码以及同时运行一些使用ProcessPoolExecutor的其他代码,使用同步代码管理这些代码并不容易,但使用asyncio非常容易。
import asyncio
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
async def with_processing():
with ProcessPoolExecutor() as executor:
tasks = [...]
for task in asyncio.as_completed(tasks):
result = await task
...
async def with_threading():
with ThreadPoolExecutor() as executor:
tasks = [...]
for task in asyncio.as_completed(tasks):
result = await task
...
async def main():
await asyncio.gather(with_processing(), with_threading())
asyncio.run(main())
asyncio 会要求执行器运行它们的函数。然后,在执行器正在运行时,asyncio 会去运行其他代码。例如,ProcessPoolExecutor 启动了一堆进程,在等待这些进程完成时,ThreadPoolExecutor 启动了一堆线程。asyncio 然后会检查这些执行器,并在它们完成时收集它们的结果。此外,如果您有其他使用 asyncio 的代码,您可以在等待进程和线程完成时运行它们。
from concurrent.futures import ThreadPoolExecutor
import requests
def get_data(url):
return requests.get(url).json()["data"]
urls = [...]
with ThreadPoolExecutor() as executor:
for data in executor.map(get_data, urls):
print(data)
json 很大,而让许多线程消耗大量内存是灾难性的。幸运的是,解决方案很简单:from concurrent.futures import ThreadPoolExecutor
import requests
urls = [...]
with ThreadPoolExecutor() as executor:
for response in executor.map(requests.get, urls):
print(response.json()["data"])
json被加载到内存中,一切都很好。get_data不像这个例子中的简单函数那样简单呢?如果我们必须在函数中间的某个深处应用执行器呢?这就是asyncio发挥作用的地方:import asyncio
import requests
async def get_data(url):
# A lot of code.
...
# The specific part that needs threading.
response = await asyncio.to_thread(requests.get, url, some_other_params)
# A lot of code.
...
return data
urls = [...]
async def main():
tasks = [get_data(url) for url in urls]
for task in asyncio.as_completed(tasks):
data = await task
print(data)
asyncio.run(main())
使用 concurrent.futures 进行同样的操作并不是很简单。你可以使用回调函数、队列等方式,但相比基本的 asyncio 代码,它将更难管理。
requests.get而不是get_data可以避免将JSON对象卸载到内存中吗?它们都是函数,为了从中返回,requests.get似乎也需要将对象卸载到内存中。 - Zac Wranglerrequests.get(...) 和 .json()["data"]。其中一个执行API请求,另一个将所需数据加载到内存中。将 threading 应用于 API 请求可能会显著提高性能,因为您的计算机不需要为其执行任何工作,只需等待下载完成即可。将 threading 应用于 .json()["data"] 可能(并且很可能)导致多个 .json() 同时启动,最终跟随 ["data"],也许在所有 .json() 都运行之后。 - Simply Beautiful Art.json()的大小乘以线程数),这对性能来说是灾难性的。使用asyncio,您可以轻松地选择使用threading运行哪些代码和不运行哪些代码,从而使您能够选择不使用threading运行.json()["data"],而是只一次加载一个。 - Simply Beautiful Artasyncio 的主要优势在于能够清晰地组织代码,提供更多避免编写不良并发代码的方式。 - Simply Beautiful Art已经有很多好的答案了,关于何时使用每个答案无法再详细阐述。这是两者的有趣组合。Multiprocessing + asyncio: https://pypi.org/project/aiomultiprocess/.
它被设计用于高IO的用例,但仍然利用尽可能多的可用核心。Facebook使用这个库编写了一些基于Python的文件服务器。Asyncio允许IO限制流量,而multiprocessing允许在多个核心上使用多个事件循环和线程。
来自存储库的示例代码:
import asyncio
from aiohttp import request
from aiomultiprocess import Pool
async def get(url):
async with request("GET", url) as response:
return await response.text("utf-8")
async def main():
urls = ["https://jreese.sh", ...]
async with Pool() as pool:
async for result in pool.map(get, urls):
... # process result
if __name__ == '__main__':
# Python 3.7
asyncio.run(main())
# Python 3.6
# loop = asyncio.get_event_loop()
# loop.run_until_complete(main())
这里只是一个补充说明,如果在例如Jupyter Notebook中使用,则无法正常工作,因为该Notebook已经有一个异步事件循环在运行。这只是一个小提示,以免让您感到恼火。
asyncio和concurrent.futures.ProcessPoolExecutor来完成大部分工作。值得注意的是,aiomultiprocessing在协程上运行,这意味着它可能会生成许多事件循环,而不是使用一个统一的事件循环(从源代码中可以看出),好坏参半。 - Simply Beautiful Artmultiprocessing 不同,它真正发挥作用的地方是运行多个事件循环。也就是说,如果您发现 asyncio 的事件循环本身已经成为瓶颈,例如由于服务器上客户端数量过多,那么这就是要选择的选项。 - Simply Beautiful Art我不是专业的Python用户,但作为一名计算机体系结构的学生,我认为我可以在选择多处理和多线程之间分享我的一些考虑。此外,一些其他答案(即使是那些得票较高的答案)滥用了技术术语,因此我认为有必要首先对它们进行一些澄清。
多进程和多线程之间的根本区别在于它们是否共享同一内存空间。线程共享访问同一虚拟内存空间,因此线程之间交换计算结果非常高效和简单(零拷贝,并且完全在用户空间执行)。
另一方面,进程拥有独立的虚拟内存空间。它们无法直接读取或写入其他进程的内存空间,就像一个人不能在没有与他交谈的情况下阅读或更改另一个人的思想一样。(这样做将违反内存保护并且会破坏使用虚拟内存的目的。)为了在进程之间交换数据,它们必须依赖于操作系统的功能(例如消息传递),出于多种原因,这比线程使用的“共享内存”方案更加昂贵。其中一个原因是调用操作系统的消息传递机制需要进行系统调用,这将使代码执行从用户模式切换到内核模式,这需要耗费时间;另一个原因可能是操作系统的消息传递方案需要将数据字节从发送者的内存空间复制到接收者的内存空间,所以存在非零复制成本。需要大量CPU计算且需要并发程序间的密集通信:如果GIL不存在,请使用多线程,或者使用另一种编程语言。
大量IO操作:使用asyncio。
多进程可以并行运行。
多线程和asyncio无法并行运行。
在拥有Intel(R) Core(TM) i7-8700K CPU @ 3.70GHz和32.0 GB RAM的计算机上,我用2个进程、2个线程和2个asyncio任务计时了从2到100000之间的质数数量。下表展示了这个CPU密集型计算的结果:
| 多进程 | 多线程 | asyncio |
|---|---|---|
| 23.87 秒 | 45.24 秒 | 44.77 秒 |
多进程因为可以并行运行,所以比多线程和asyncio快将近两倍,如上表所示。
我使用了以下3组代码:
# "process_test.py"
from multiprocessing import Process
import time
start_time = time.time()
def test():
num = 100000
primes = 0
for i in range(2, num + 1):
for j in range(2, i):
if i % j == 0:
break
else:
primes += 1
print(primes)
if __name__ == "__main__": # This is needed to run processes on Windows
process_list = []
for _ in range(0, 2): # 2 processes
process = Process(target=test)
process_list.append(process)
for process in process_list:
process.start()
for process in process_list:
process.join()
print(round((time.time() - start_time), 2), "seconds") # 23.87 seconds
结果:
...
9592
9592
23.87 seconds
# "thread_test.py"
from threading import Thread
import time
start_time = time.time()
def test():
num = 100000
primes = 0
for i in range(2, num + 1):
for j in range(2, i):
if i % j == 0:
break
else:
primes += 1
print(primes)
thread_list = []
for _ in range(0, 2): # 2 threads
thread = Thread(target=test)
thread_list.append(thread)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
print(round((time.time() - start_time), 2), "seconds") # 45.24 seconds
结果:
...
9592
9592
45.24 seconds
# "asyncio_test.py"
import asyncio
import time
start_time = time.time()
async def test():
num = 100000
primes = 0
for i in range(2, num + 1):
for j in range(2, i):
if i % j == 0:
break
else:
primes += 1
print(primes)
async def call_tests():
tasks = []
for _ in range(0, 2): # 2 asyncio tasks
tasks.append(test())
await asyncio.gather(*tasks)
asyncio.run(call_tests())
print(round((time.time() - start_time), 2), "seconds") # 44.77 seconds
结果:
...
9592
9592
44.77 seconds
多进程 每个进程都有自己的Python解释器,并且可以在处理器的不同核心上运行。Python的multiprocessing是一个支持使用类似于线程模块的API来生成进程的包。multiprocessing包提供真正的并行性,通过使用子进程而不是线程有效地绕过全局解释器锁。
当您有CPU密集型任务时,请使用multiprocessing。
多线程 Python的多线程允许您在进程内生成多个线程。这些线程可以共享进程的相同内存和资源。在CPython中,由于全局解释器锁,在任何给定时间只能运行单个线程,因此无法利用多个核心。由于GIL的限制,Python中的多线程不提供真正的并行性。
Asyncio Asyncio基于协作式多任务概念工作。Asyncio任务在同一线程上运行,因此没有并行性,但它为开发人员提供了比多线程更好的控制,这是在多线程中的情况下操作系统提供的。
关于asyncio优于线程的优点,可以参考此链接进行讨论。
Lei Mao在Python并发性方面有一篇不错的博客在这里
asyncio和multithreading之间添加一个代码示例,因为我在这篇文章中没有看到一个:asyncio运行的代码,输出是确定性的。import asyncio
async def foo():
print('Start foo()')
for x in range(10):
await asyncio.sleep(0.1)
print(x, "foooo", x, "foooo",)
print('End foo()')
async def bar():
print('Start bar()')
for x in range(10):
await asyncio.sleep(0.1)
print(x, "barrr", x, "barrr",)
print('End bar()')
async def main():
await asyncio.gather(foo(), bar())
asyncio.run(main())
输出:
Start foo()
Start bar()
0 foooo 0 foooo
0 barrr 0 barrr
1 foooo 1 foooo
1 barrr 1 barrr
2 foooo 2 foooo
2 barrr 2 barrr
3 foooo 3 foooo
3 barrr 3 barrr
4 foooo 4 foooo
4 barrr 4 barrr
5 foooo 5 foooo
5 barrr 5 barrr
6 foooo 6 foooo
6 barrr 6 barrr
7 foooo 7 foooo
7 barrr 7 barrr
8 foooo 8 foooo
8 barrr 8 barrr
9 foooo 9 foooo
End foo()
9 barrr 9 barrr
End bar()
import threading
import time
def foo():
print('Start foo()')
for x in range(10):
time.sleep(0.1)
print(x, "foooo", x, "foooo",)
print('End foo()')
def bar():
print('Start bar()')
for x in range(10):
time.sleep(0.1)
print(x, "barrr", x, "barrr",)
print('End bar()')
t1 = threading.Thread(target=foo)
t2 = threading.Thread(target=bar)
t1.start()
t2.start()
t1.join()
t2.join()
输出:
Start bar()Start foo()
0 0 foooo 0 foooo
barrr 0 barrr
11 foooo barrr 11 foooobarrr
22 foooobarrr 22 barrr
foooo
3 3 barrr foooo3 3 foooobarrr
44 barrr 4 barrr
foooo 4 foooo
55 barrr foooo5 5barrr
foooo
66 foooo 6 barrr foooo
6 barrr
7 7 foooo 7 foooo
barrr 7 barrr
88 foooo 8 foooo
barrr 8 barrr
99 foooo barrr 99 foooobarrr
End foo()
End bar()
{kind=link}