我在查询方面遇到了一个小问题。
SELECT DISTINCT ON ("reporting_processedamazonsnapshot"."offer_id") *
FROM "reporting_processedamazonsnapshot" INNER JOIN
"offers_boooffer"
ON ("reporting_processedamazonsnapshot"."offer_id" =
"offers_boooffer"."id") INNER JOIN
"offers_offersettings"
ON ("offers_boooffer"."id" = "offers_offersettings"."offer_id")
WHERE "offers_offersettings"."account_id" = 20
ORDER BY "reporting_processedamazonsnapshot"."offer_id" ASC,
"reporting_processedamazonsnapshot"."scraping_date" DESC
我有一个名为
latest_scraping的索引,按照offer_id ASC, scraping_date DESC排序,但由于某种原因,PostgreSQL在使用索引后仍然进行排序,导致性能问题严重。我不明白为什么它不使用已经排序好的数据,而要重新排序。我的索引是有问题吗?或者我应该尝试用另一种方式查询?
下面是带有实际数据的解释:
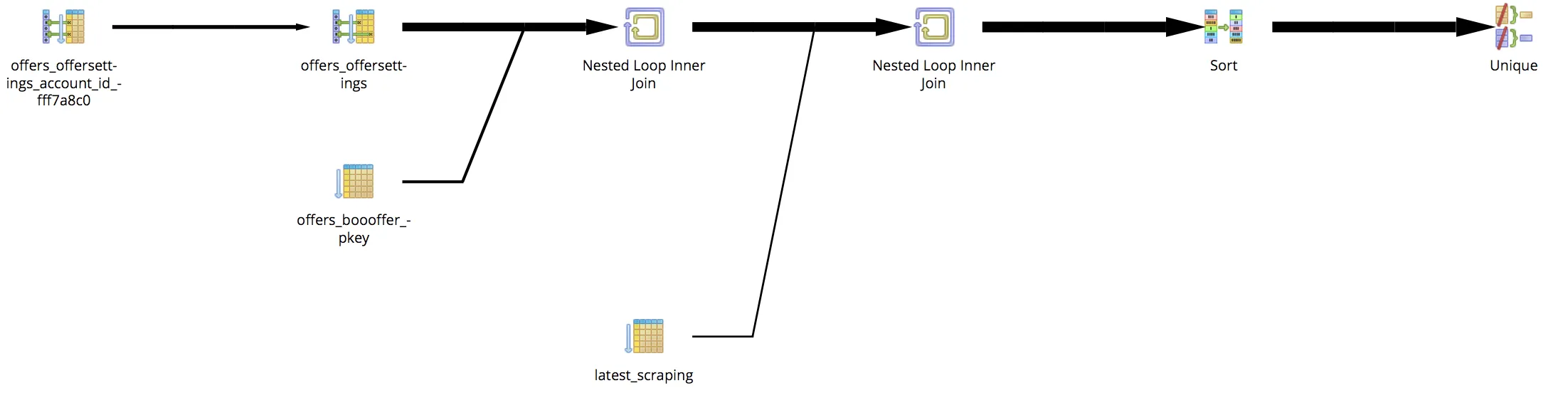
'Unique (cost=21260.47..21263.06 rows=519 width=1288) (actual time=38053.685..38177.348 rows=1783 loops=1)'
' -> Sort (cost=21260.47..21261.76 rows=519 width=1288) (actual time=38053.683..38161.478 rows=153095 loops=1)'
' Sort Key: reporting_processedamazonsnapshot.offer_id, reporting_processedamazonsnapshot.scraping_date DESC'
' Sort Method: external merge Disk: 162088kB'
' -> Nested Loop (cost=41.90..21237.06 rows=519 width=1288) (actual time=70.874..36148.348 rows=153095 loops=1)'
' -> Nested Loop (cost=41.47..17547.90 rows=1627 width=8) (actual time=54.287..126.740 rows=1784 loops=1)'
' -> Bitmap Heap Scan on offers_offersettings (cost=41.04..4823.48 rows=1627 width=4) (actual time=52.532..84.102 rows=1784 loops=1)'
' Recheck Cond: (account_id = 20)'
' Heap Blocks: exact=38'
' -> Bitmap Index Scan on offers_offersettings_account_id_fff7a8c0 (cost=0.00..40.63 rows=1627 width=0) (actual time=49.886..49.886 rows=4132 loops=1)'
' Index Cond: (account_id = 20)'
' -> Index Only Scan using offers_boooffer_pkey on offers_boooffer (cost=0.43..7.81 rows=1 width=4) (actual time=0.019..0.020 rows=1 loops=1784)'
' Index Cond: (id = offers_offersettings.offer_id)'
' Heap Fetches: 1784'
' -> Index Scan using latest_scraping on reporting_processedamazonsnapshot (cost=0.43..1.69 rows=58 width=1288) (actual time=0.526..20.146 rows=86 loops=1784)'
' Index Cond: (offer_id = offers_boooffer.id)'
'Planning time: 187.133 ms'
'Execution time: 38195.266 ms'