假设我有以下字典数据集列表:
我需要迭代字典列表,将键作为列标题,将值作为行,然后将其写入CSV文件。
为了简洁起见,我将键减少到2个,值的列表减少到3个。
如何解决这个问题?
谢谢
data_set = [
{'Active rate': [0.98, 0.97, 0.96]},
{'Operating Expense': [3.104, 3.102, 3.101]}
]
我需要迭代字典列表,将键作为列标题,将值作为行,然后将其写入CSV文件。
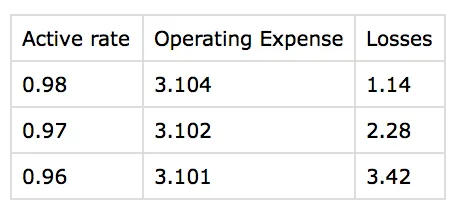
Active rate Operating Expense
0.98 3.104
0.97 3.102
0.96 3.101
这是我尝试过的方法
data_set = [
{'Active rate': [0.98, 0.931588, 0.941192]},
{'Operating Expense': [3.104, 2.352, 2.304]}
]
import csv
with open('names.csv', 'w') as csvfile:
fieldnames = ['Active rate', 'Operating Expense']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'Active rate': 0.98, 'Operating Expense': 3.102})
writer.writerow({'Active rate': 0.97, 'Operating Expense': 3.11})
writer.writerow({'Active rate': 0.96, 'Operating Expense': 3.109})
为了简洁起见,我将键减少到2个,值的列表减少到3个。
如何解决这个问题?
谢谢