我正在尝试从字符字符串中删除/提取邮政编码。逻辑是我正在获取以下内容:
注意:R的正则表达式与其他正则表达式类似,但是特定于R。这个问题是关于R的正则表达式而不是一般的正则表达式问题。
- 必须包含正好5个连续数字或
- 必须包含正好5个连续数字,后跟连字符,然后正好4个连续数字或
- 必须包含正好5个连续数字,后跟空格,然后正好4个连续数字
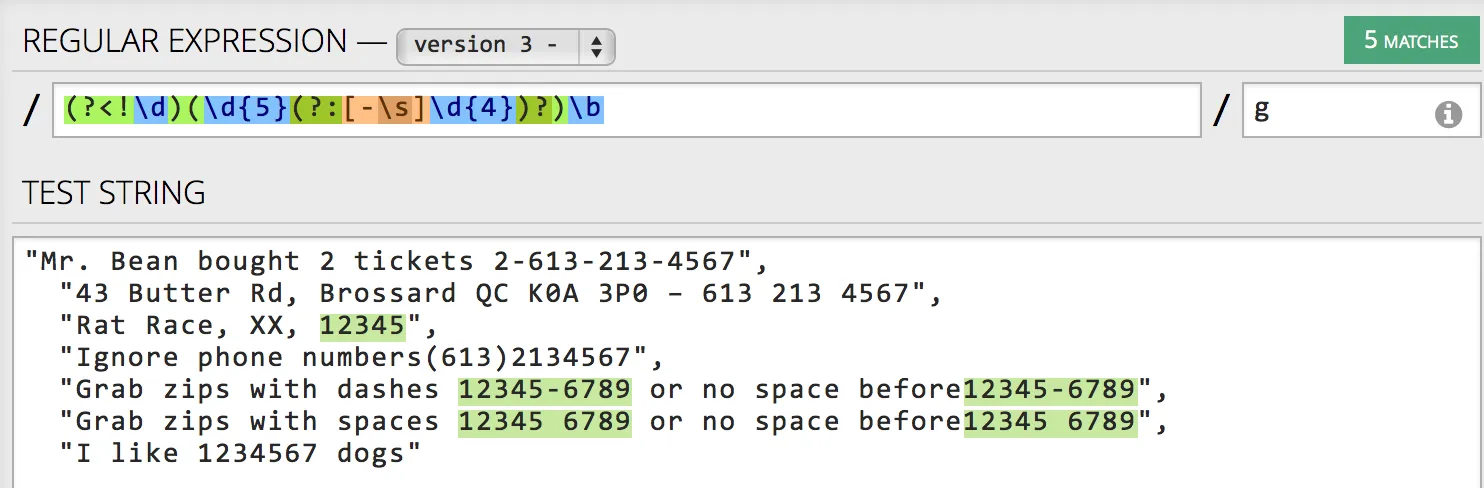
text.var <- c("Mr. Bean bought 2 tickets 2-613-213-4567",
"43 Butter Rd, Brossard QC K0A 3P0 – 613 213 4567",
"Rat Race, XX, 12345",
"Ignore phone numbers(613)2134567",
"Grab zips with dashes 12345-6789 or no space before12345-6789",
"Grab zips with spaces 12345 6789 or no space before12345 6789",
"I like 1234567 dogs"
)
pattern1 <- "\\d{5}([- ]*\\d{4})?"
pattern2 <- "[0-9]{5}(-[0-9]{4})?(?!.*[0-9]{5}(-[0-9]{4})?)"
regmatches(text.var, gregexpr(pattern1, text.var, perl = TRUE))
regmatches(text.var, gregexpr(pattern2, text.var, perl = TRUE))
## [[1]]
## character(0)
##
## [[2]]
## character(0)
##
## [[3]]
## [1] "12345"
##
## [[4]]
## [1] "21345"
##
## [[5]]
## [1] "12345-6789"
##
## [[6]]
## [1] "12345"
##
## [[7]]
## [1] "12345"
期望的输出
## [[1]]
## character(0)
##
## [[2]]
## character(0)
##
## [[3]]
## [1] "12345"
##
## [[4]]
## character(0)
##
## [[5]]
## [1] "12345-6789" "12345-6789"
##
## [[6]]
## [1] "12345 6789" "12345 6789"
##
## [[7]]
## character(0)
注意:R的正则表达式与其他正则表达式类似,但是特定于R。这个问题是关于R的正则表达式而不是一般的正则表达式问题。
perl=TRUE时,您也可以使用 perl 正则表达式,因此通常经典的正则表达式是一种 R 解决方案。 - agstudy