word2vec:负采样是什么意思?(通俗易懂解释)
1
word2vec的思想是最大化文本中彼此接近(上下文中)出现的单词向量之间的相似度(点积),并最小化不相关单词的相似度。在你提供的论文中的方程式(3)中,暂时忽略指数运算符。你有:
v_c . v_w
-------------------
sum_i(v_ci . v_w)
3
word2vec,对于任何给定的单词,你都有一个单词列表,这些单词需要与它相似(即正类),但不相似的单词列表(即负类)是通过采样生成的。 - mbatchkarov计算 Softmax(用于确定哪些单词与当前目标单词相似)的代价很高,因为需要对V中所有单词求和(分母),而V通常非常大。
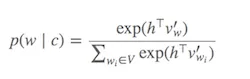
怎么办呢?
提出了不同的策略来近似Softmax。这些方法可以分为基于softmax和基于采样的方法。 基于softmax 的方法保持softmax层不变,但修改其结构以提高效率(如层次softmax)。 另一方面,基于采样 的方法完全放弃了softmax层,并优化某些其他逼近softmax的损失函数(它们通过用一些便宜的损失(如负采样)逼近softmax中分母的归一化来实现)。
Word2vec中的损失函数类似于:
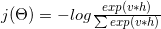
可以分解为对数函数:
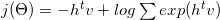
通过一些数学和梯度公式(详见6),可以将其转换为:
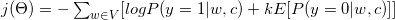
当我们将其转化为二元分类任务时(y=1代表正例,y=0代表负例),需要标签来执行这个二元分类任务。因此,我们将所有的上下文词 c 指定为真实标签(y=1,正例样本),并且从语料库中随机选择k作为假标签(y=0,负例样本)。
看下面的段落。假设我们的目标单词是“Word2vec”。在窗口大小为3的情况下,我们的上下文单词是:The、widely、popular、algorithm、was、developed。这些上下文单词被认为是正标签。我们还需要一些负标签。我们从语料库中随机挑选一些单词(produce、software、Collobert、margin-based、probabilistic)并将它们视为负样本。我们采用从语料库中随机选择一些例子的技术称为负采样。

参考资料:
- (1) C. Dyer, "Notes on Noise Contrastive Estimation and Negative Sampling", 2014
- (2) http://sebastianruder.com/word-embeddings-softmax/
3
香草Skip-Gram(SG)和Skip-Gram负采样(SGNS)的成本函数如下:
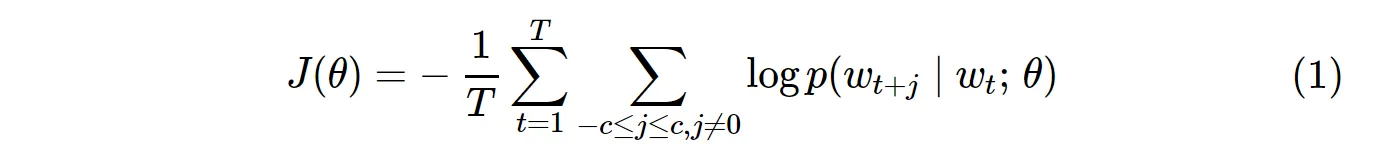
T代表所有词汇数。它等同于V。换句话说,T = V。在SG中,针对语料库中的所有
V个词汇,使用以下公式计算概率分布p(w_t+j|w_t):
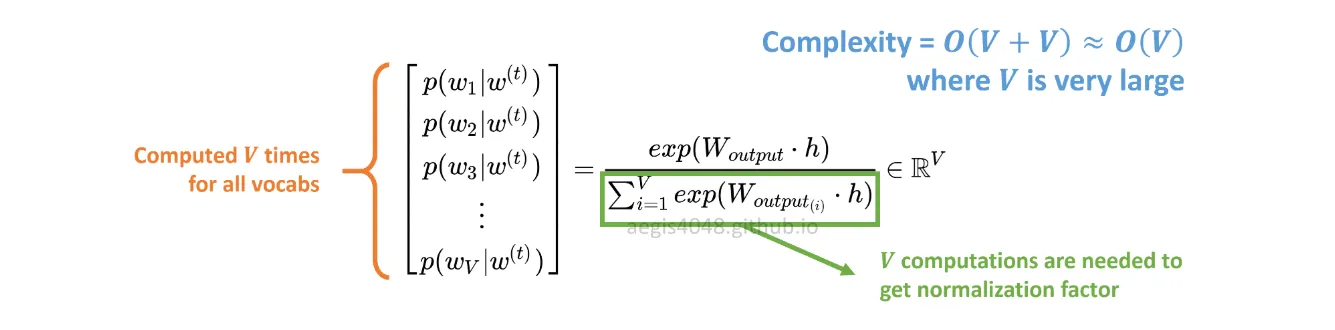
V 在训练 Skip-Gram 模型时很容易超过数万。需要计算 V 次概率,使其在计算上变得昂贵。此外,分母中的归一化因子需要额外的 V 次计算。
另一方面,在 SGNS 中计算概率分布的方法是:
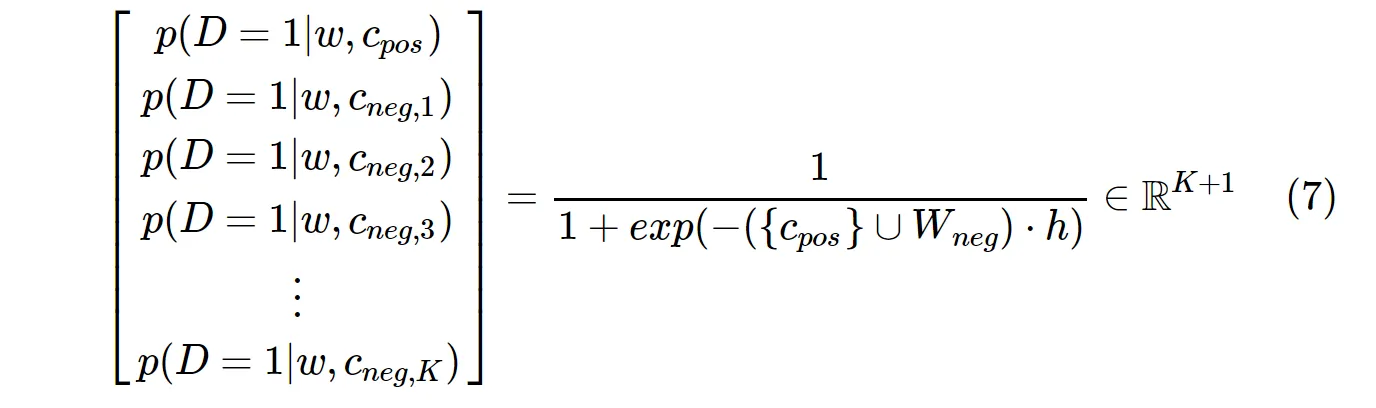
c_pos 是表示正面词的词向量,W_neg 是表示输出权重矩阵中所有 K 个负样本的词向量。使用 SGNS 算法时,只需要计算概率 K + 1 次,其中 K 通常在 5 ~ 20 之间。此外,在分母中计算归一化因子时不需要额外的迭代。
使用 SGNS 算法时,每个训练样本只更新一小部分权重,而 SG 算法会为每个训练样本更新数百万个权重。
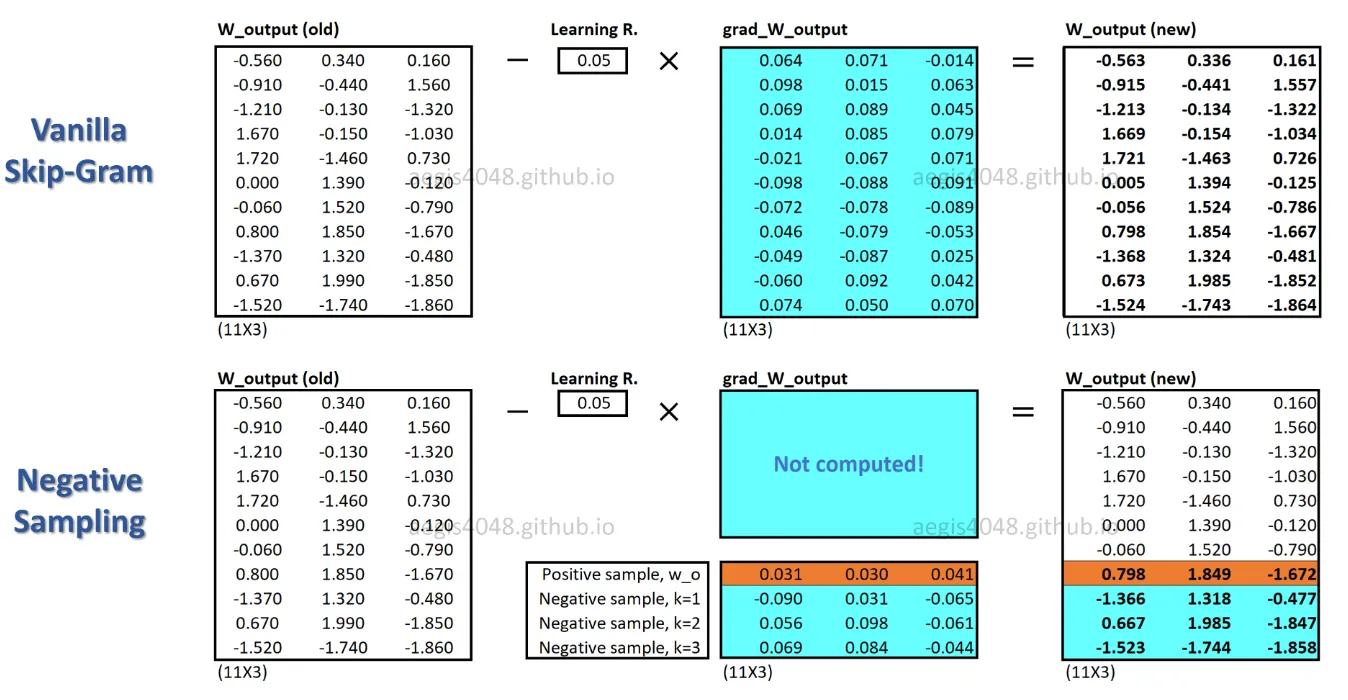
使用{{SGNS}},词向量不再是通过预测中心词的上下文词来学习。它学习区分实际上下文词(正样本)和从噪声分布中随机抽取的词(负样本)。


drilling, engineer)。从噪声分布中随机抽取K=5个负样本: minimized, primary, concerns, led, page。随着模型遍历训练样本,权重被优化,以便于正样本的概率输出p(D=1|w,c_pos)≈1,并且负样本的概率输出p(D=1|w,c_neg)≈0。3
K 设置为 V-1,那么负采样就与普通的skip-gram模型相同。我的理解正确吗? - Shashwat原文链接