我正在使用Python进行黎曼积分的实验。
我有几个函数:
当我将其放置在pandas DataFrame中时,键的顺序也会混乱,导致另一个错误。
在发布之前,我阅读了相关内容,并看到有时获取值的repr()函数会起作用,但这并没有奏效。
我认为增加列宽可能会有所帮助,但这只适用于值列,而不是索引(无论如何,在创建字典时出现问题,而不是在DF本身)。
def myfunc(x, mu, sigma):
px = np.exp(-(x-mu)**2/(2*sigma**2))
return px
def get_area(h,mu,sigma):
x = np.arange(-100,100+h,h)
return sum([myfunc(xi,mu,sigma)*h for xi in x])
我正在尝试探索mu和sigma的变化对函数下面积的影响。我是这样做的:
sigma_range = [0.25,0.5,1,2]
h_range = [2,1,0.1,0.001,0.00001]
result_dict = {}
for sigma in sigma_range:
sigma_dict = {}
for h in h_range:
sigma_dict[str(repr(h))] = sigma_dict.get(str(h), [])
sigma_dict[str(repr(h))].append(get_area(h,1,sigma))
result_dict[str(sigma)] = sigma_dict
经过调查,其中一个sigma值(作为键)被截断。"0.00001"变成了"1e-05"。
result_dict["0.25"]
{'2': [0.0013418505116100474],
'1': [1.0006709252558303],
'0.1': [0.6266570686577856],
'0.001': [0.6266570686547552],
'1e-05': [0.6266570684587373]}
当我将其放置在pandas DataFrame中时,键的顺序也会混乱,导致另一个错误。
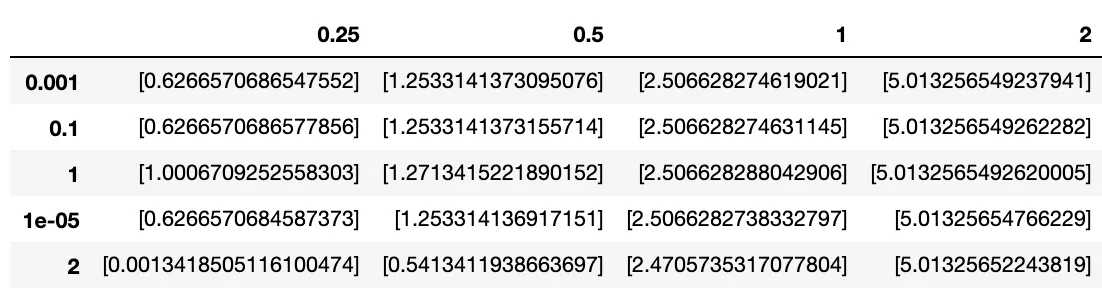
在发布之前,我阅读了相关内容,并看到有时获取值的repr()函数会起作用,但这并没有奏效。
我认为增加列宽可能会有所帮助,但这只适用于值列,而不是索引(无论如何,在创建字典时出现问题,而不是在DF本身)。
0.00001到1e-05没有任何更改。 - LeoE