作为一个在家研究项目的一部分,我正在尝试找到一种将歌曲降噪/转换成哼唱音频信号的方法(即我们听歌时感知到的潜在旋律)。在继续描述我对这个问题的尝试之前,我想提醒一下,尽管我有大量分析图像和视频的经验,但我完全是一个新手,没有音频分析经验。
通过搜索Google,我找到了一堆旋律提取算法。给定一首多声部音频信号(例如.wav文件),它们输出一个音高轨迹——在每个时间点估计主导音高(来自歌手的声音或某种旋律生成器的声音)并跟踪随时间变化的主导音高。
我阅读了几篇论文,它们似乎计算了歌曲的短时Fourier变换,然后在谱图上进行一些分析,以获取和跟踪主导音高。旋律提取只是我正试图开发的系统中的一个组件,所以只要它可以对我的音频文件进行良好的处理,并且代码可用,我就不介意使用任何可用的算法。由于我是新手,我很乐意听取关于哪些算法已知能够很好地工作以及如何找到其代码的任何建议。
我找到了两个算法:
我选择了Melodia,因为不同音乐类型的结果看起来非常令人印象深刻。请参见此处查看其结果。你听到的每一首歌的哼唱声基本上就是我感兴趣的内容。
“这个问题我需要你的帮助解决,即对于任意歌曲生成这种哼唱声。”
该算法(作为vamp插件提供)输出一个音高轨迹——[时间戳,音高/频率]——一个Nx2矩阵,在第一列中是时间戳(秒),第二列是在相应时间戳检测到的主导音高。下面是从算法获得的音高轨迹与歌曲时域信号(上方)和其谱图/短时傅里叶变换叠加在一起的可视化。负值的音高/频率代表未发声/非旋律段的算法主导音高估计。因此,所有音高估计>=0都对应于旋律,其余则不重要。
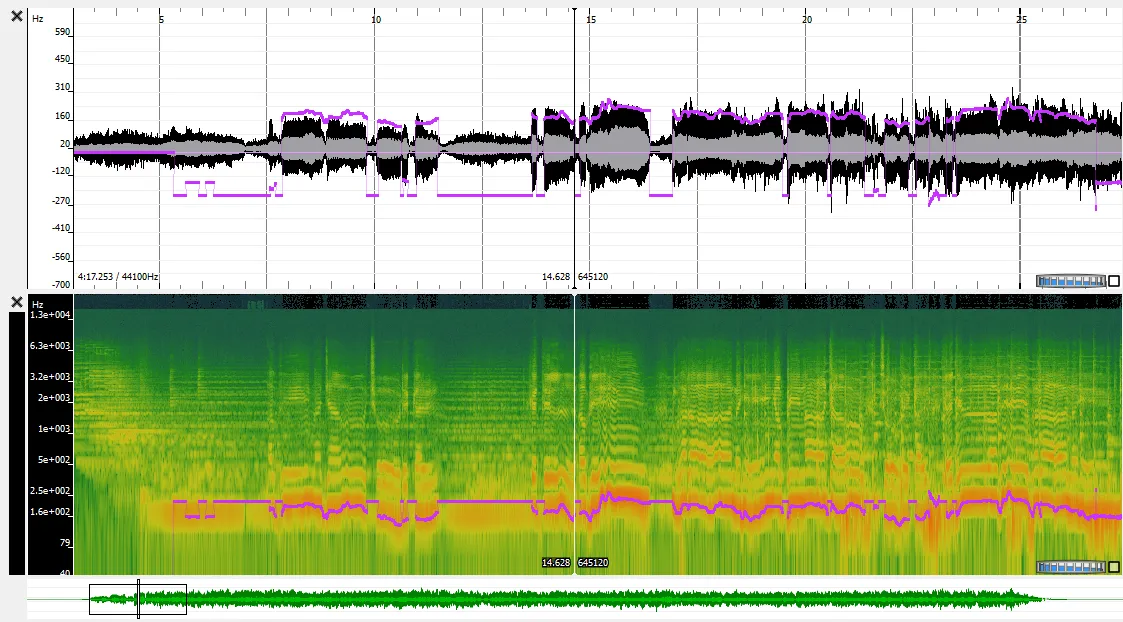
现在我想将这个音高轨迹转换回类似哼唱声的音频信号-就像作者在他们的网站上展示的那样。
下面是我编写的MATLAB函数:
function [melSignal] = melody2audio(melody, varargin)
% melSignal = melody2audio(melody, Fs, synthtype)
% melSignal = melody2audio(melody, Fs)
% melSignal = melody2audio(melody)
%
% Convert melody/pitch-track to a time-domain signal
%
% Inputs:
%
% melody - [time-stamp, dominant-frequency]
% an Nx2 matrix with time-stamp in the
% first column and the detected dominant
% frequency at corresponding time-stamp
% in the second column.
%
% synthtype - string to choose synthesis method
% passed to synth function in synth.m
% current choices are: 'fm', 'sine' or 'saw'
% default='fm'
%
% Fs - sampling frequency in Hz
% default = 44.1e3
%
% Output:
%
% melSignal -- time-domain representation of the
% melody. When you play this, you
% are supposed to hear a humming
% of the input melody/pitch-track
%
p = inputParser;
p.addRequired('melody', @isnumeric);
p.addParamValue('Fs', 44100, @(x) isnumeric(x) && isscalar(x));
p.addParamValue('synthtype', 'fm', @(x) ismember(x, {'fm', 'sine', 'saw'}));
p.addParamValue('amp', 60/127, @(x) isnumeric(x) && isscalar(x));
p.parse(melody, varargin{:});
parameters = p.Results;
% get parameter values
Fs = parameters.Fs;
synthtype = parameters.synthtype;
amp = parameters.amp;
% generate melody
numTimePoints = size(melody,1);
endtime = melody(end,1);
melSignal = zeros(1, ceil(endtime*Fs));
h = waitbar(0, 'Generating Melody Audio' );
for i = 1:numTimePoints
% frequency
freq = max(0, melody(i,2));
% duration
if i > 1
n1 = floor(melody(i-1,1)*Fs)+1;
dur = melody(i,1) - melody(i-1,1);
else
n1 = 1;
dur = melody(i,1);
end
% synthesize/generate signal of given freq
sig = synth(freq, dur, amp, Fs, synthtype);
N = length(sig);
% augment note to whole signal
melSignal(n1:n1+N-1) = melSignal(n1:n1+N-1) + reshape(sig,1,[]);
% update status
waitbar(i/size(melody,1));
end
close(h);
end
这段代码的基本逻辑如下:在每个时间点,我合成一个短暂的波形(例如正弦波),其频率等于该时间点检测到的主导音调/频率,并持续时间等于它与输入旋律矩阵中下一个时间戳之间的差距。我只是在想是否正确执行了此操作。
然后,我从此函数获得的音频信号并将其与原始歌曲一起播放(旋律在左声道,原始歌曲在右声道)。尽管生成的音频信号似乎相当好地分割了产生旋律的来源(声音/主音器乐)-在声音所在处活动,在其他地方为零-但信号本身远非像作者在他们的网站上展示的哼唱(我得到的是beep beep beeeeep beep beeep beeeeeeeep)。具体而言,下面是显示输入歌曲时间域信号和使用我的函数生成的旋律时间域信号的可视化。
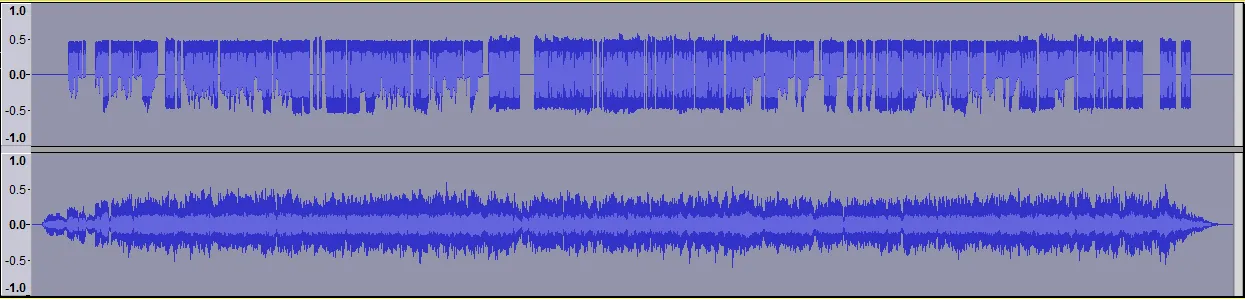
一个主要问题是-尽管我在每个时间戳上都给出了要生成的波的频率和持续时间,但我不知道如何设置波的幅度。目前,我将幅度设置为平坦/恒定值,并且我怀疑这就是问题所在。
有人对此有什么建议吗?我欢迎任何编程语言(最好是MATLAB、Python、C++)的建议,但我想这里我的问题更加普遍——如何在每个时间戳上生成波形?
我脑海中有几个想法/修复方法:
- 通过从原始歌曲的时间域信号中获取幅度的平均值/最大估计来设置幅度。
- 完全改变我的方法——计算歌曲音频信号的谱图/短时傅里叶变换。截断/零或软地消除所有其他频率,除了在我的音高跟踪中(或接近我的音高跟踪)的那些频率。然后计算反短时傅里叶变换以获得时间域信号。