代码1:
vzeroall mov rcx, 1000000 startLabel1: vfmadd231ps ymm0, ymm0, ymm0 vfmadd231ps ymm1, ymm1, ymm1 vfmadd231ps ymm2, ymm2, ymm2 vfmadd231ps ymm3, ymm3, ymm3 vfmadd231ps ymm4, ymm4, ymm4 vfmadd231ps ymm5, ymm5, ymm5 vfmadd231ps ymm6, ymm6, ymm6 vfmadd231ps ymm7, ymm7, ymm7 vfmadd231ps ymm8, ymm8, ymm8 vfmadd231ps ymm9, ymm9, ymm9 vpaddd ymm10, ymm10, ymm10 vpaddd ymm11, ymm11, ymm11 vpaddd ymm12, ymm12, ymm12 vpaddd ymm13, ymm13, ymm13 vpaddd ymm14, ymm14, ymm14 dec rcx jnz startLabel1Code2:
vzeroall mov rcx, 1000000 startLabel2: vmulps ymm0, ymm0, ymm0 vmulps ymm1, ymm1, ymm1 vmulps ymm2, ymm2, ymm2 vmulps ymm3, ymm3, ymm3 vmulps ymm4, ymm4, ymm4 vmulps ymm5, ymm5, ymm5 vmulps ymm6, ymm6, ymm6 vmulps ymm7, ymm7, ymm7 vmulps ymm8, ymm8, ymm8 vmulps ymm9, ymm9, ymm9 vpaddd ymm10, ymm10, ymm10 vpaddd ymm11, ymm11, ymm11 vpaddd ymm12, ymm12, ymm12 vpaddd ymm13, ymm13, ymm13 vpaddd ymm14, ymm14, ymm14 dec rcx jnz startLabel2代码3(与代码2相同,但具有较长的VEX前缀):
vzeroall
mov rcx, 1000000
startLabel3:
byte 0c4h, 0c1h, 07ch, 059h, 0c0h ;long VEX form vmulps ymm0, ymm0, ymm0
byte 0c4h, 0c1h, 074h, 059h, 0c9h ;long VEX form vmulps ymm1, ymm1, ymm1
byte 0c4h, 0c1h, 06ch, 059h, 0d2h ;long VEX form vmulps ymm2, ymm2, ymm2
byte 0c4h, 0c1h, 06ch, 059h, 0dbh ;long VEX form vmulps ymm3, ymm3, ymm3
byte 0c4h, 0c1h, 05ch, 059h, 0e4h ;long VEX form vmulps ymm4, ymm4, ymm4
byte 0c4h, 0c1h, 054h, 059h, 0edh ;long VEX form vmulps ymm5, ymm5, ymm5
byte 0c4h, 0c1h, 04ch, 059h, 0f6h ;long VEX form vmulps ymm6, ymm6, ymm6
byte 0c4h, 0c1h, 044h, 059h, 0ffh ;long VEX form vmulps ymm7, ymm7, ymm7
vmulps ymm8, ymm8, ymm8
vmulps ymm9, ymm9, ymm9
vpaddd ymm10, ymm10, ymm10
vpaddd ymm11, ymm11, ymm11
vpaddd ymm12, ymm12, ymm12
vpaddd ymm13, ymm13, ymm13
vpaddd ymm14, ymm14, ymm14
dec rcx
jnz startLabel3
Code4(与Code1相同,但使用xmm寄存器):
vzeroall
mov rcx, 1000000
startLabel4:
vfmadd231ps xmm0, xmm0, xmm0
vfmadd231ps xmm1, xmm1, xmm1
vfmadd231ps xmm2, xmm2, xmm2
vfmadd231ps xmm3, xmm3, xmm3
vfmadd231ps xmm4, xmm4, xmm4
vfmadd231ps xmm5, xmm5, xmm5
vfmadd231ps xmm6, xmm6, xmm6
vfmadd231ps xmm7, xmm7, xmm7
vfmadd231ps xmm8, xmm8, xmm8
vfmadd231ps xmm9, xmm9, xmm9
vpaddd xmm10, xmm10, xmm10
vpaddd xmm11, xmm11, xmm11
vpaddd xmm12, xmm12, xmm12
vpaddd xmm13, xmm13, xmm13
vpaddd xmm14, xmm14, xmm14
dec rcx
jnz startLabel4
Code5(与Code1相同,但使用vpsubd的非零值):
vzeroall
mov rcx, 1000000
startLabel5:
vfmadd231ps ymm0, ymm0, ymm0
vfmadd231ps ymm1, ymm1, ymm1
vfmadd231ps ymm2, ymm2, ymm2
vfmadd231ps ymm3, ymm3, ymm3
vfmadd231ps ymm4, ymm4, ymm4
vfmadd231ps ymm5, ymm5, ymm5
vfmadd231ps ymm6, ymm6, ymm6
vfmadd231ps ymm7, ymm7, ymm7
vfmadd231ps ymm8, ymm8, ymm8
vfmadd231ps ymm9, ymm9, ymm9
vpsubd ymm10, ymm10, ymm11
vpsubd ymm11, ymm11, ymm12
vpsubd ymm12, ymm12, ymm13
vpsubd ymm13, ymm13, ymm14
vpsubd ymm14, ymm14, ymm10
dec rcx
jnz startLabel5
Code6b:(修改,仅适用于vpaddds的内存操作数)
vzeroall
mov rcx, 1000000
startLabel6:
vfmadd231ps ymm0, ymm0, ymm0
vfmadd231ps ymm1, ymm1, ymm1
vfmadd231ps ymm2, ymm2, ymm2
vfmadd231ps ymm3, ymm3, ymm3
vfmadd231ps ymm4, ymm4, ymm4
vfmadd231ps ymm5, ymm5, ymm5
vfmadd231ps ymm6, ymm6, ymm6
vfmadd231ps ymm7, ymm7, ymm7
vfmadd231ps ymm8, ymm8, ymm8
vfmadd231ps ymm9, ymm9, ymm9
vpaddd ymm10, ymm10, [mem]
vpaddd ymm11, ymm11, [mem]
vpaddd ymm12, ymm12, [mem]
vpaddd ymm13, ymm13, [mem]
vpaddd ymm14, ymm14, [mem]
dec rcx
jnz startLabel6
代码7: (与代码1相同,但vpaddds使用ymm15)
vzeroall
mov rcx, 1000000
startLabel7:
vfmadd231ps ymm0, ymm0, ymm0
vfmadd231ps ymm1, ymm1, ymm1
vfmadd231ps ymm2, ymm2, ymm2
vfmadd231ps ymm3, ymm3, ymm3
vfmadd231ps ymm4, ymm4, ymm4
vfmadd231ps ymm5, ymm5, ymm5
vfmadd231ps ymm6, ymm6, ymm6
vfmadd231ps ymm7, ymm7, ymm7
vfmadd231ps ymm8, ymm8, ymm8
vfmadd231ps ymm9, ymm9, ymm9
vpaddd ymm10, ymm15, ymm15
vpaddd ymm11, ymm15, ymm15
vpaddd ymm12, ymm15, ymm15
vpaddd ymm13, ymm15, ymm15
vpaddd ymm14, ymm15, ymm15
dec rcx
jnz startLabel7
Code8:(与Code7相同,但使用xmm而不是ymm)
vzeroall
mov rcx, 1000000
startLabel8:
vfmadd231ps xmm0, ymm0, ymm0
vfmadd231ps xmm1, xmm1, xmm1
vfmadd231ps xmm2, xmm2, xmm2
vfmadd231ps xmm3, xmm3, xmm3
vfmadd231ps xmm4, xmm4, xmm4
vfmadd231ps xmm5, xmm5, xmm5
vfmadd231ps xmm6, xmm6, xmm6
vfmadd231ps xmm7, xmm7, xmm7
vfmadd231ps xmm8, xmm8, xmm8
vfmadd231ps xmm9, xmm9, xmm9
vpaddd xmm10, xmm15, xmm15
vpaddd xmm11, xmm15, xmm15
vpaddd xmm12, xmm15, xmm15
vpaddd xmm13, xmm15, xmm15
vpaddd xmm14, xmm15, xmm15
dec rcx
jnz startLabel8
Haswell Broadwell Skylake
CPUID 306C3, 40661 306D4, 40671 506E3
Code1 ~5000000 ~7730000 ->~54% slower ~5500000 ->~10% slower
Code2 ~5000000 ~5000000 ~5000000
Code3 ~6000000 ~5000000 ~5000000
Code4 ~5000000 ~7730000 ~5500000
Code5 ~5000000 ~7730000 ~5500000
Code6b ~5000000 ~8380000 ~5500000
Code7 ~5000000 ~5000000 ~5000000
Code8 ~5000000 ~5000000 ~5000000
Code1在Broadwell上会发生什么?我的猜测是,对于Code1情况,Broadwell会以某种方式污染Port1与vpaddds,然而Haswell只能使用Port5,如果Port0和Port1已满。
您有任何想法如何在Broadwell上使用FMA指令实现~5000000 clk吗?
我尝试重新排序。双精度和qword经历了类似的行为;
我使用了Windows 8.1和Win 10;
更新:
添加了Code3作为Marat Dukhan的长VEX思路;
扩展了Skylake经验的结果表;
上传了一个VS2015 Community + MASM示例代码here
更新2:
我尝试使用xmm寄存器代替ymm(Code 4)。Broadwell上的结果相同。
更新3:
我添加了Code5作为Peter Cordes的思路(使用其他指令(vpxor,vpor,vpand,vpandn,vpsubd)替换vpaddd)。如果新指令不是零元算符(vpxor,vpsubd与同一寄存器),则在BDW上结果相同。已使用Code4和Code5更新示例项目。
更新4:
我添加了Code6作为Stephen Canon的思路(内存操作数)。结果是~8200000 clks。使用Code6更新示例项目;
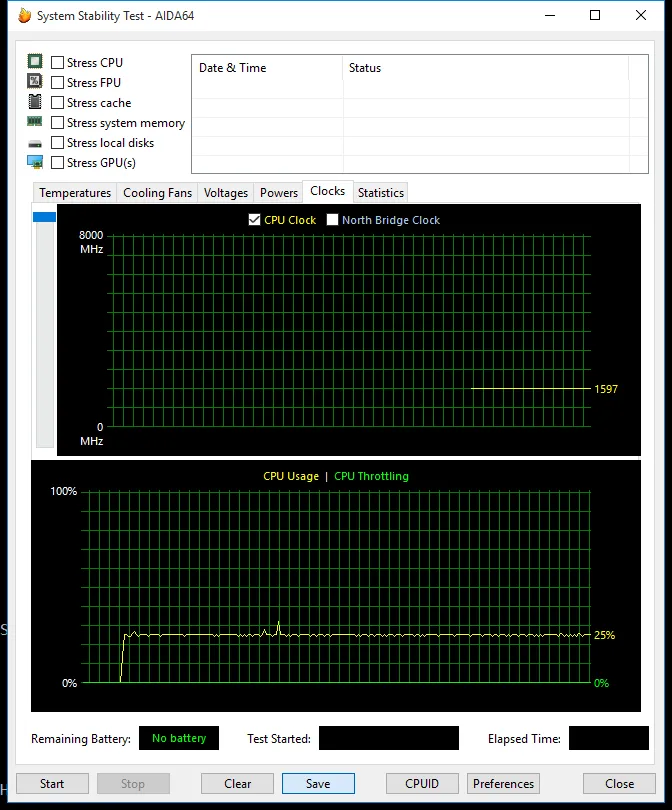
我检查了CPU频率和AIDA64系统稳定测试中的可能抑制。频率稳定,没有抑制迹象;
Intel IACA 2.1 Haswell吞吐量分析:
Intel(R) Architecture Code Analyzer Version - 2.1 Analyzed File - Assembly.obj Binary Format - 64Bit Architecture - HSW Analysis Type - Throughput Throughput Analysis Report -------------------------- Block Throughput: 5.10 Cycles Throughput Bottleneck: Port0, Port1, Port5 Port Binding In Cycles Per Iteration: --------------------------------------------------------------------------------------- | Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 | --------------------------------------------------------------------------------------- | Cycles | 5.0 0.0 | 5.0 | 0.0 0.0 | 0.0 0.0 | 0.0 | 5.0 | 1.0 | 0.0 | --------------------------------------------------------------------------------------- | Num Of | Ports pressure in cycles | | | Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 | | --------------------------------------------------------------------------------- | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm0, ymm0, ymm0 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm1, ymm1, ymm1 | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm2, ymm2, ymm2 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm3, ymm3, ymm3 | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm4, ymm4, ymm4 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm5, ymm5, ymm5 | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm6, ymm6, ymm6 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm7, ymm7, ymm7 | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm8, ymm8, ymm8 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm9, ymm9, ymm9 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm10, ymm10, ymm10 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm11, ymm11, ymm11 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm12, ymm12, ymm12 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm13, ymm13, ymm13 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm14, ymm14, ymm14 | 1 | | | | | | | 1.0 | | | dec rcx | 0F | | | | | | | | | | jnz 0xffffffffffffffaa Total Num Of Uops: 16根据Peter Cordes的提醒,Code6已更改,只有vpaddds使用内存操作数。对HSW和SKL没有影响,对BDW更糟。
根据Marat Dukhan的测量结果,不仅vpadd/vpsub/vpand/vpandn/vpxor受到影响,还有其他Port5受限指令,如vmovaps、vblendps、vpermps、vshufps、vbroadcastss;
正如IwillnotexistIdonotexist所建议的那样,我尝试使用其他操作数。成功修改的版本是Code7,其中所有vpaddds均使用ymm15。这个版本在BDWs上可以产生约5000000个时钟周期,但仅持续了一段时间。经过约600万个FMA对后,它达到了通常的约7730000个时钟周期:
我尝试了Code7的xmm版本,就像Code8一样。效果类似,但更快的运行时间持久更长。我没有发现1.6GHz i5-5250U和3.7GHz i7-5775C之间有显着的差异。
禁用HyperThreading制作了16和17。启用HTT效果较差。
Clock Core cyc Instruct uop p0 uop p1 uop p5 uop p6
Code1: 7734720 7734727 17000001 4983410 5016592 5000001 1000001
Code2: 5000072 5000072 17000001 5000010 5000014 4999978 1000002
端口分配与Haswell基本一致。然后我检查了资源停顿计数器(事件0xa2)。
Clock Core cyc Instruct res.stl. RS stl. SB stl. ROB stl.
Code1: 7736212 7736213 17000001 3736191 3736143 0 0
Code2: 5000068 5000072 17000001 1000050 999957 0 0
据我看来,Code1和Code2的差别似乎是由于RS停滞引起的。Intel SDM中的注释是:“由于没有符合要求的RS条目可用而导致的周期停滞。”
如何使用FMA避免这种停滞?
更新5:
Clock Core cyc Instruct res.stl. RS stl. SB stl. ROB stl.
5133724 5110723 17000001 1107998 946376 0 0
6545476 6545482 17000001 2545453 1 0 0
6545468 6545471 17000001 2545437 90910 0 0
5000016 5000019 17000001 999992 999992 0 0
7671620 7617127 17000003 3614464 3363363 0 0
7737340 7737345 17000001 3737321 3737259 0 0
7802916 7747108 17000003 3737478 3735919 0 0
7928784 7796057 17000007 3767962 3676744 0 0
7941072 7847463 17000003 3781103 3651595 0 0
7787812 7779151 17000005 3765109 3685600 0 0
7792524 7738029 17000002 3736858 3736764 0 0
7736000 7736007 17000001 3735983 3735945 0 0


VFMADD231PS ymm0,ymm0,ymm0是一个 5 字节的指令(3 字节的 VEX 前缀),而VMULPS ymm0,ymm0,ymm0是一个 4 字节的指令(2 字节的 VEX 前缀)。你确定问题不是由于 ifetch/decoder 引起的吗? - Marat Dukhan