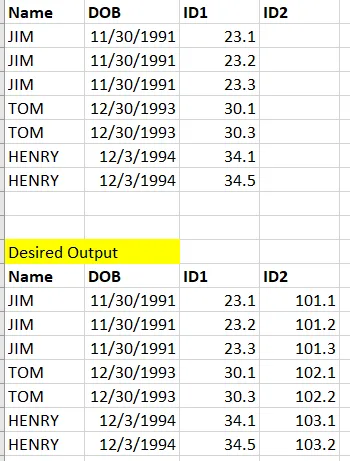
假设您希望ID2值与ID1值的顺序相同,并且没有重复的ID1值,您可以使用具有适当窗口子句的分析函数来完成此操作,而无需使用序列。
select name, dob, id1,
100 + dense_rank() over (order by trunc(id1))
+ dense_rank() over (partition by trunc(id1) order by id1)/10
as id2
from table1;
NAME DOB ID1 ID2
JIM 1991-11-30 23.1 101.1
JIM 1991-11-30 23.2 101.2
JIM 1991-11-30 23.3 101.3
TOM 1993-12-30 30.1 102.1
TOM 1993-12-30 30.2 102.2
HENRY 1994-12-03 34.1 103.1
HENRY 1994-12-03 34.2 103.2
7 rows selected.
您可以将生成的表作为合并语句的一部分使用:
merge into table1
using (
select name, dob, id1,
100 + dense_rank() over (order by trunc(id1))
+ dense_rank() over (partition by trunc(id1) order by id1)/10
as id2
from table1
) tmp on (tmp.id1 = table1.id1)
when matched then
update set table1.id2 = tmp.id2;
7 rows merged.
select * from table1;
NAME DOB ID1 ID2
JIM 1991-11-30 23.1 101.1
JIM 1991-11-30 23.2 101.2
JIM 1991-11-30 23.3 101.3
TOM 1993-12-30 30.1 102.1
TOM 1993-12-30 30.2 102.2
HENRY 1994-12-03 34.1 103.1
HENRY 1994-12-03 34.2 103.2
7 rows selected.
db<>fiddle
如果ID2与ID1无关,则可以按照任何顺序进行排序:
merge into table1
using (
select name, dob, id1,
100 + dense_rank() over (order by name, dob)
+ dense_rank() over (partition by name, dob order by id1)/10
as id2
from table1
) tmp on (tmp.id1 = table1.id1)
when matched then
update set table1.id2 = tmp.id2;
select * from table1;
NAME DOB ID1 ID2
JIM 1991-11-30 23.1 102.1
JIM 1991-11-30 23.2 102.2
JIM 1991-11-30 23.3 102.3
TOM 1993-12-30 30.1 103.1
TOM 1993-12-30 30.2 103.2
HENRY 1994-12-03 34.1 101.1
HENRY 1994-12-03 34.2 101.2
这仅在小数部分不超过0.9的情况下才有效;但是,如果超过了0.9,那么很难解释这些值(例如23.10与23.1相同)。
我还假设,我想,这是一次性更新,您不打算将序列用于未来的插入;不清楚您如何管理它 - 只有在姓名/生日不存在时,您才需要获取下一个序列值,如果存在,则需要找到最高现有ID并将其加上0.1。无论哪种方式,都必须对插入进行串行化,以防止冲突或不一致。
实际上,它进入了这样一种情况:ID1值为23.10、23.11,而ID2将它们显示为101.1、101.1。
...我尝试将其除以100,针对>= .11的值问题已得到解决,但对于.10和.20仍显示为.1和.2。
这表明两个ID值都是字符串而不是数字。如果是这样,您仍然可以使用排名函数,但将生成的两个数字视为字符串并将它们连接在一起。
merge into table1
using (
select name, dob, id1,
to_char(100 + dense_rank() over (order by name, dob))
||'.'||
dense_rank() over (partition by name, dob
order by to_number(substr(id1, instr(id1, '.') + 1)))
as id2
from table1
) tmp on (tmp.id1 = table1.id1)
when matched then
update set table1.id2 = tmp.id2;
With some additional base data that gives you:
select * from table1;
NAME DOB ID1 ID2
JIM 1991-11-30 23.1 103.1
JIM 1991-11-30 23.2 103.2
JIM 1991-11-30 23.3 103.3
TOM 1993-12-30 30.1 104.1
TOM 1993-12-30 30.3 104.2
HENRY 1993-12-30 34.1 101.1
HENRY 1994-12-03 34.5 102.1
HENRY 1994-12-03 34.6 102.2
HENRY 1994-12-03 34.7 102.3
HENRY 1994-12-03 34.8 102.4
HENRY 1994-12-03 34.9 102.5
HENRY 1994-12-03 34.10 102.6
HENRY 1994-12-03 34.11 102.7
HENRY 1994-12-03 34.12 102.8
HENRY 1994-12-03 34.13 102.9
HENRY 1994-12-03 34.14 102.10
HENRY 1994-12-03 34.15 102.11
HENRY 1994-12-03 34.16 102.12
db<>fiddle
当然,这样做会使得将ID2值视为数字或有意义地进行排序变得非常困难;但是对于ID1值而言,这种情况可能已经存在。另一种选择可能是将第一部分乘以一个大数,比如1000,然后再加上第二部分——这样亨利的ID将变成1020001到1010012之间的数字。