在存在许多自定义堆分配器实例的环境中,以下陈述是否正确?:-
Each allocated pointer should be encapsulated in a type (e.g.
Ptr)
that cache pointer of who allocated me (Allo*) e.g.class Ptr={ Allo* alloPtr; //<-- to keep track public: void delete(){ //call back to something like "a.deallocate()" } } Allo a; //a custom allocator Ptr<X> x=a.allocate<X>(); x.delete();I think I need to do that to make
delete()easier.If the allocator is more complex, e.g. internally keep a lot of chunks :-
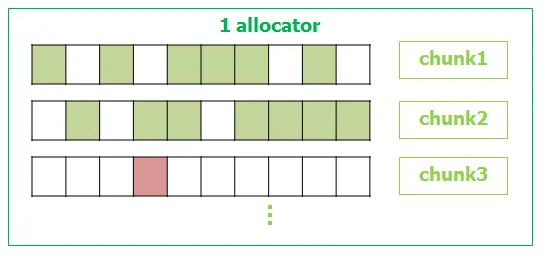
Ptrshould keep track which chunk it resides on, OR
there must be some tiny flag before the allocated content :-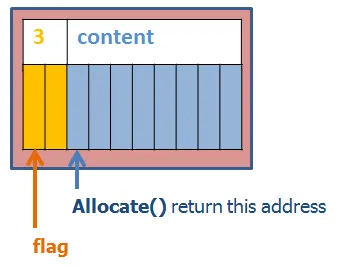
Otherwise, I have to iterate each chunk to find the address -> low performance.
对于自定义分配器我非常新手,如果这太简单了,那我很抱歉。这不是作业 - 我正在尝试改进我的游戏库。
我已经阅读了: