EXISTS和IN在SQL中有何区别?
何时应使用EXISTS,何时应使用IN?
哪种方式更快取决于内部查询获取的查询数:
EXIST评估为真或假,但IN比较多个值。当您不知道记录是否存在时,请选择EXIST。
NULL值时,整个语句就会变成NULL。在这种情况下,我们使用EXISTS关键字。如果我们想比较子查询中的特定值,则使用IN关键字。如果你可以使用where in代替where exists,那么where in可能更快。
使用where in或where exists将遍历父结果的所有结果。区别在于,where exists会导致大量的依赖子查询。如果你可以避免依赖子查询,那么where in将是更好的选择。
例子
假设我们有10,000家公司,每家公司有10个用户(因此我们的用户表有100,000条记录)。现在假设你想通过他的名字或公司名找到一个用户。
以下使用were exists的查询执行时间为141毫秒:
select * from `users`
where `first_name` ='gates'
or exists
(
select * from `companies`
where `users`.`company_id` = `companies`.`id`
and `name` = 'gates'
)
 但是,如果我们避免使用exists查询并改用:
但是,如果我们避免使用exists查询并改用:select * from `users`
where `first_name` ='gates'
or users.company_id in
(
select id from `companies`
where `name` = 'gates'
)
那么,避免了依赖子查询,查询运行时间为0.012毫秒

如果子查询返回多个值,则可能需要执行外部查询-如果条件中指定的列中的值与子查询结果集中的任何值匹配。要执行此任务,您需要使用in关键字。
您可以使用子查询来检查是否存在一组记录。为此,您需要使用带有子查询的exists子句。 exists关键字始终返回true或false值。
我发现在编程中使用 EXISTS 关键字通常非常慢(在 Microsoft Access 中很明显)。相反,我会以这种方式使用连接运算符: should-i-use-the-keyword-exists-in-sql
我对最近使用的一个查询进行了一些练习。我最初使用INNER JOIN创建了它,但我想看看用EXISTS会是什么样子/效果如何。我进行了转换。我将在此处包含两个版本以供比较。
SELECT DISTINCT Category, Name, Description
FROM [CodeSets]
WHERE Category NOT IN (
SELECT def.Category
FROM [Fields] f
INNER JOIN [DataEntryFields] def ON f.DataEntryFieldId = def.Id
INNER JOIN Section s ON f.SectionId = s.Id
INNER JOIN Template t ON s.Template_Id = t.Id
WHERE t.AgencyId = (SELECT Id FROM Agencies WHERE Name = 'Some Agency')
AND def.Category NOT IN ('OFFLIST', 'AGENCYLIST', 'RELTO_UNIT', 'HOSPITALS', 'EMS', 'TOWCOMPANY', 'UIC', 'RPTAGENCY', 'REP')
AND (t.Name like '% OH %')
AND (def.Category IS NOT NULL AND def.Category <> '')
)
ORDER BY 1
以下是统计数据:
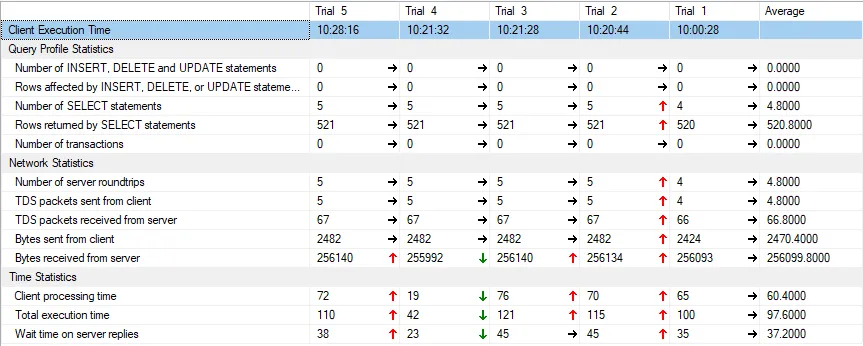
这是转换后的版本:
SELECT DISTINCT cs.Category, Name, Description
FROM [CodeSets] cs
WHERE NOT Exists (
SELECT * FROM [Fields] f
WHERE EXISTS (SELECT * FROM [DataEntryFields] def
WHERE def.Id = f.DataEntryFieldId
AND def.Category NOT IN ('OFFLIST', 'AGENCYLIST', 'RELTO_UNIT', 'HOSPITALS', 'EMS', 'TOWCOMPANY', 'UIC', 'RPTAGENCY', 'REP')
AND (def.Category IS NOT NULL AND def.Category <> '')
AND def.Category = cs.Category
AND EXISTS (SELECT * FROM Section s
WHERE f.SectionId = s.Id
AND EXISTS (SELECT * FROM Template t
WHERE s.Template_Id = t.Id
AND EXISTS (SELECT * FROM Agencies
WHERE Name = 'Some Agency' and t.AgencyId = Id)
AND (t.Name like '% OH %')
)
)
)
)
ORDER BY 1
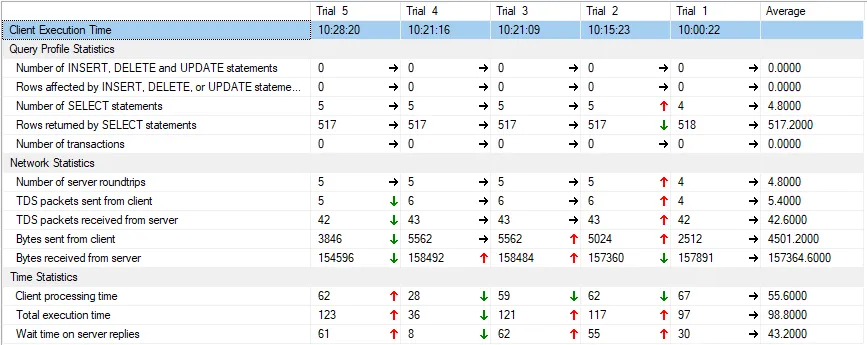 如果我对SQL的工作原理更了解,我可以给你一个答案,但是你可以从这个例子中得出自己的结论。
如果我对SQL的工作原理更了解,我可以给你一个答案,但是你可以从这个例子中得出自己的结论。