我有一个非常大的 n*m 矩阵 S。我希望能够高效地确定是否存在一个子矩阵 F 在 S 中。这个大矩阵 S 的大小可以达到 500*500。
为了澄清,考虑以下情况:
S = 1 2 3
4 5 6
7 8 9
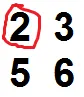
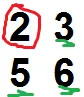
F1 = 2 3
5 6
F2 = 1 2
4 6
在这种情况下:
-
F1 在 S 中
- F2 不在 S 中矩阵中的每个元素都是一个32位整数。我只能想到使用暴力方法来查找
F 是否为S 的子矩阵。我谷歌搜索了一下,但没有找到有效的算法。是否有一些算法或原则可以更快地完成它?(或者可能有一些方法来优化暴力方法?)
附:统计数据
A total of 8 S
On average, each S will be matched against about 44 F.
The probability of success match (i.e. F appears in a S) is
19%.
 中查找
中查找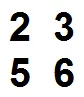

 -
- 