3个回答
60
在ASN.1标记中,实际上有两个目的:类型和命名。 类型意味着它告诉编码器/解码器这是什么数据类型(是字符串、整数、布尔值、集合等),命名意味着如果存在多个相同类型的字段并且某些(或全部)是可选的,它告诉编码器/解码器该值属于哪个字段。
如果将ASN.1与JSON进行比较,并查看以下JSON数据:
你会注意到在JSON中,每个字段都明确命名(“Image”,“Width”,“Height”,“Title”),并且明确或隐含地指定了类型(“Title”是字符串,因为它的值被引号包围,“Width”是整数,因为它只有数字,而不是“null”,“true”或“false”,也没有小数点)。
在ASN.1中,这段数据将是:
这将不需要任何特殊标记即可工作,这里只需要使用通用标记。通用标记不命名数据,只是对数据进行分类,因此编码器和解码器知道前两个值是整数,最后一个值是字符串。第一个整数是宽度,第二个整数是高度,并不需要在字节流中进行编码,它们的顺序已经定义好了(序列有一个固定的顺序,集合没有。在你所提到的页面上使用的是集合)。
现在按以下方式更改模式:
好的,现在我们有一个问题。假设接收到以下数据:
你知道750是高度而不是宽度(实际上没有宽度)。在这里,你声明了一个新标签(在这种情况下是上下文相关的),它有两个目的:一是告诉编码器/解码器这是一个整数值(类型),二是告诉它这是哪个整数值(命名)。
那么隐式标记和显式标记有什么区别呢?区别在于隐式标记只命名数据,编码器/解码器需要隐式地知道该名称的类型,而显式标记则命名并明确指定数据类型。
如果标记是显式的,数据将被发送为:
即使解码器不知道[1]代表高度,它也知道应该将“xxx”字节解析/解释为整数值。显式标记的另一个重要优点是可以在不更改标记的情况下更改类型。例如。
一个不知道[1]是什么的解码器,将无法知道"xxx"的类型,因此无法正确地解析/解释该数据。与JSON不同,ASN.1中的值只是字节。因此,“xxx”可能是一个、两个、三个或四个字节,如何解码这些字节取决于它们的数据类型,在数据流本身中没有提供。同时,更改[1]的类型肯定会破坏现有的解码器。
好吧,但为什么会有人使用隐式标记?总是使用显式标记不是更好吗?对于显式标记,类型也必须编码在数据流中,这将需要每个标记额外的两个字节。对于包含几千(甚至数百万)个标记的数据传输,以及可能每个字节都很重要(非常缓慢的连接,小数据包,高数据包丢失率,处理设备非常薄弱),并且双方都已经知道所有自定义标记,为什么要浪费带宽、内存、存储和/或处理时间来编码、传输和解码不必要的类型信息呢?
请记住,ASN.1是一个相当古老的标准,旨在在网络带宽非常昂贵、处理器比今天慢几百倍的时候实现高度紧凑的数据表示。如果您看一下今天所有XML和JSON数据传输,甚至考虑节省每个标记的两个字节似乎都是荒谬的。
如果将ASN.1与JSON进行比较,并查看以下JSON数据:
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor"
}
你会注意到在JSON中,每个字段都明确命名(“Image”,“Width”,“Height”,“Title”),并且明确或隐含地指定了类型(“Title”是字符串,因为它的值被引号包围,“Width”是整数,因为它只有数字,而不是“null”,“true”或“false”,也没有小数点)。
在ASN.1中,这段数据将是:
Image ::= SEQUENCE {
Width INTEGER,
Height INTEGER,
Title UTF8String
}
这将不需要任何特殊标记即可工作,这里只需要使用通用标记。通用标记不命名数据,只是对数据进行分类,因此编码器和解码器知道前两个值是整数,最后一个值是字符串。第一个整数是宽度,第二个整数是高度,并不需要在字节流中进行编码,它们的顺序已经定义好了(序列有一个固定的顺序,集合没有。在你所提到的页面上使用的是集合)。
现在按以下方式更改模式:
Image ::= SEQUENCE {
Width INTEGER OPTIONAL,
Height INTEGER OPTIONAL,
Title UTF8String
}
好的,现在我们有一个问题。假设接收到以下数据:
INTEGER(750), UTF8String("A funny kitten")
750是什么?宽度还是高度?可能是宽度(且缺少高度),也可能是高度(且缺少宽度),在二进制流中两者看起来相同。在JSON中,每个数据块都有名称,因此很清晰,但在ASN.1中则不然。现在仅有类型已经不够了,我们还需要一个名称。这就是非通用标签的作用。将其更改为:
Image ::= SEQUENCE {
Width [0] INTEGER OPTIONAL,
Height [1] INTEGER OPTIONAL,
Title UTF8String
}
如果您收到以下数据:
[1]INTEGER(750), UTF8String("A funny kitten")
你知道750是高度而不是宽度(实际上没有宽度)。在这里,你声明了一个新标签(在这种情况下是上下文相关的),它有两个目的:一是告诉编码器/解码器这是一个整数值(类型),二是告诉它这是哪个整数值(命名)。
那么隐式标记和显式标记有什么区别呢?区别在于隐式标记只命名数据,编码器/解码器需要隐式地知道该名称的类型,而显式标记则命名并明确指定数据类型。
如果标记是显式的,数据将被发送为:
[1]INTEGER(xxx), UTF8String(yyy)
即使解码器不知道[1]代表高度,它也知道应该将“xxx”字节解析/解释为整数值。显式标记的另一个重要优点是可以在不更改标记的情况下更改类型。例如。
Length ::= [0] INTEGER
可以被更改为
Length ::= [0] CHOICE {
integer INTEGER,
real REAL
}
标记[0]仍然表示长度,但现在长度可以是整数或浮点值。由于类型被显式编码,解码器将始终知道如何正确解码该值,因此这种更改在向前和向后兼容(至少在解码器级别上是向后兼容的,不一定在应用程序级别上是向后兼容的)。
如果标记是隐式的,则数据将被发送为:
[1](xxx), UTF8String(yyy)
一个不知道[1]是什么的解码器,将无法知道"xxx"的类型,因此无法正确地解析/解释该数据。与JSON不同,ASN.1中的值只是字节。因此,“xxx”可能是一个、两个、三个或四个字节,如何解码这些字节取决于它们的数据类型,在数据流本身中没有提供。同时,更改[1]的类型肯定会破坏现有的解码器。
好吧,但为什么会有人使用隐式标记?总是使用显式标记不是更好吗?对于显式标记,类型也必须编码在数据流中,这将需要每个标记额外的两个字节。对于包含几千(甚至数百万)个标记的数据传输,以及可能每个字节都很重要(非常缓慢的连接,小数据包,高数据包丢失率,处理设备非常薄弱),并且双方都已经知道所有自定义标记,为什么要浪费带宽、内存、存储和/或处理时间来编码、传输和解码不必要的类型信息呢?
请记住,ASN.1是一个相当古老的标准,旨在在网络带宽非常昂贵、处理器比今天慢几百倍的时候实现高度紧凑的数据表示。如果您看一下今天所有XML和JSON数据传输,甚至考虑节省每个标记的两个字节似乎都是荒谬的。
- Mecki
3
参考:https://osqa-ask.wireshark.org/questions/8277/difference-between-implicit-and-explicit-tags-asn1。在这里,a)A :: = INTEGER的值为5,编码为hex 02 01 05,b)B :: = [2] IMPLICIT INTEGER的值为5,编码为hex 82 01 05,c)C :: = [2] EXPLICIT INTEGER的值为5,编码为hex A2 03 02 01 05。请问有人可以解释一下b和c的情况吗? - AVA
1@AVA 如果你有问题,为什么不直接问呢?为什么要把问题放在评论里?SO是关于提问的,所以赶紧提出你的问题吧。 - Mecki
@Mecki,JSON比较非常有帮助——谢谢你。 - David Blevins
2
使用最初的回答作为编码示例:
一个编码的例子如下:
Image ::= SEQUENCE {
Width INTEGER,
Height INTEGER,
Title UTF8String
}
一个编码的例子如下:

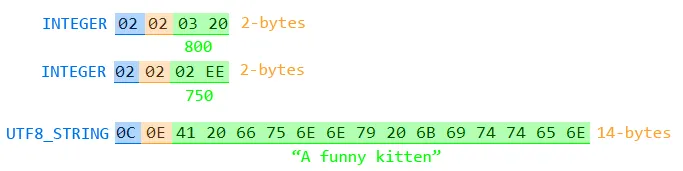
显式可选项
如果您有显式可选项值:Image ::= SEQUENCE {
Width [0] EXPLICIT INTEGER OPTIONAL,
Height [1] EXPLICIT INTEGER OPTIONAL,
Title UTF8String
}
编码序列可能是:
- SEQUENCE
30 15 A1 02 02 02 EE 0C 0E 41 20 66 75 6E 6E 79 20 6B 69 74 74 65 6E(21个字节)
而内部序列分解为:
- CONTEXT[1] INTEGER:
A1020202 EE750 (2个字节) - UTF8STRING:
0C0E41 20 66 75 6E 6E 79 20 6B 69 74 74 65 6E"一个有趣的小猫" (14个字节)
(注:其中“Original Answer”无需翻译,因为它是英文)
- Ian Boyd
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接