我有一个看起来像这样的数据集:
Out Revolver Ratio Num ...
0 1 0.766127 0.802982 0 ...
1 0 0.957151 0.121876 1
2 0 0.658180 0.085113 0
3 0 0.233810 0.036050 3
4 1 0.907239 0.024926 5
...
Out 只能取值 0 和 1。
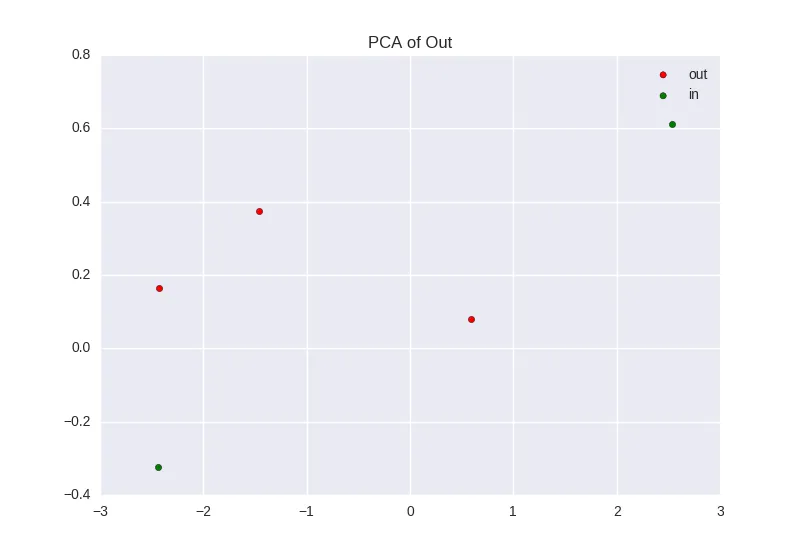
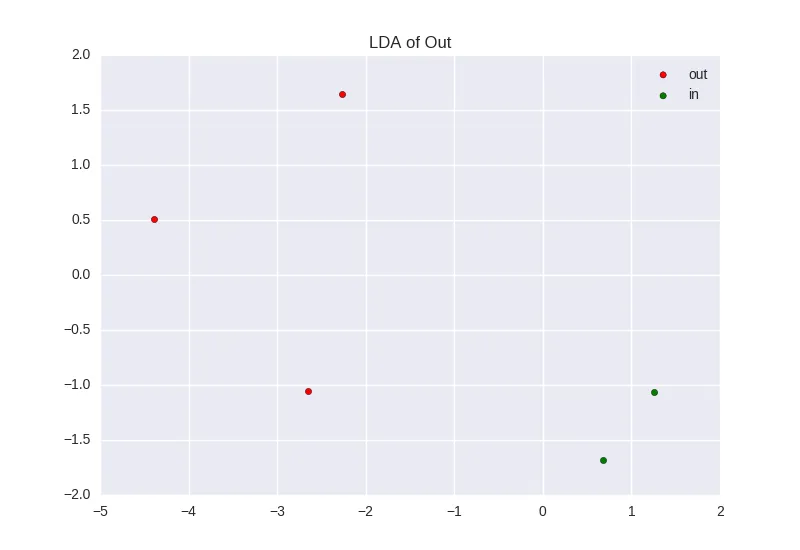
然后我尝试使用下面的代码生成类似于这里的 PCA 和 LCA 图:http://scikit-learn.org/stable/auto_examples/decomposition/plot_pca_vs_lda.html
features = Train.columns[1:]
Xf = newTrain[features]
yf = newTrain.Out
pca = PCA(n_components=2)
X_r = pca.fit(Xf).transform(Xf)
lda = LinearDiscriminantAnalysis(n_components=2)
X_r2 = lda.fit(Xf, yf).transform(Xf)
plt.figure()
for c, i, name in zip("rgb", [0, 1], names):
plt.scatter(X_r[yf == i, 0], X_r[yf == i, 1], c=c, label=name)
plt.legend()
plt.title('PCA plt')
plt.figure()
for c, i, name in zip("rgb", [0, 1], names):
plt.scatter(X_r2[yf == i, 0], X_r2[yf == i, 1], c=c, label=name)
plt.legend()
plt.title('LDA plt')
我可以让PCA图表正常工作。然而,它只显示两个点,这是没有意义的。一个位于(-4000,30)左右,另一个位于(2400,23.7)。我没有看到像该链接中的图表中那样的大量数据点。
LDA图表无法正常工作,出现了以下错误:
IndexError:轴1的大小为1,索引1超出了范围。
我还尝试使用下面的代码生成LDA图表,但出现了相同的错误。
for c, i, name in zip("rgb", [0, 1], names):
plt.scatter(x=X_LDA_sklearn[:, 0][yf==i], y=X_LDA_sklearn[:, 1][yf==i], c=c, label=name)
plt.legend()
有人知道这是什么问题吗?
编辑:这是我的导入内容
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import csv
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.lda import LDA
关于错误发生的位置:
我得到了:
FutureWarning: in the future, boolean array-likes will be handled as a boolean array index
plt.scatter(X_r[yf == i,0], X_r[yf == i, 1], c=c, label=name)
在PCA图的for循环内部的那一行
至于LDA,在那一行
plt.scatter(X_r2[yf == i, 0], X_r2[yf == i, 1], c=c, label=name)
我明白了
FutureWarning: in the future, boolean array-likes will be handled as a boolean array index
并且
IndexError: index 1 is out of bounds for axis 1 with size 1
import语句并告诉我们出现错误的行吗? - ClebTrain和newTrain是如何定义的?你是如何读取数据的?显然这是一个维度问题,如果你告诉我们你是如何创建所使用的数据的,那将会非常有帮助 :) - Cleball_cols=上面加入一行X=trainDF。 - user5739619