我有两台电脑通过1Gbps直连以太网线连接。其中一台作为TCP服务器,另一台作为TCP客户端。现在我想在这两台电脑之间实现最大可能的网络吞吐量。
我尝试了以下选项: 在PC-1上创建多个使用不同端口号的客户端,连接到TCP服务器。创建多个客户端的原因是为了增加网络吞吐量,但是我在这里遇到了一个问题。
现在让我们来看看问题:服务器以稍微随机的方式接收数据,如图所示。在一段时间后,两个连续事件之间的随机性变得更加严重。我认为这种随机行为是由于并行工作线程执行IO完成回调引起的。
使用的技术:F#套接字异步和SocketEventArgs。
我尝试的解决方案是:不是允许在服务器端从所有客户端接收,而是尝试轮询具有挂起数据的下一个可用客户端,然后可以确保正确的顺序,但其性能根本无法与以前的方法相比。
我尝试了以下选项: 在PC-1上创建多个使用不同端口号的客户端,连接到TCP服务器。创建多个客户端的原因是为了增加网络吞吐量,但是我在这里遇到了一个问题。
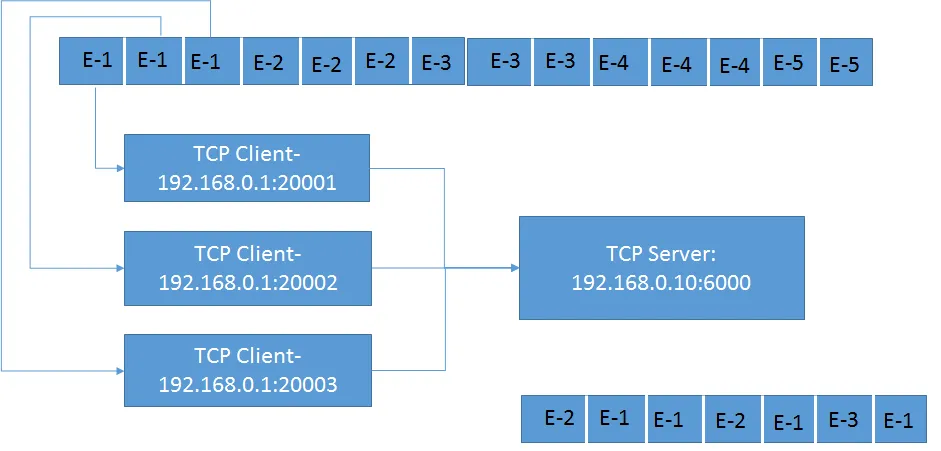
现在让我们来看看问题:服务器以稍微随机的方式接收数据,如图所示。在一段时间后,两个连续事件之间的随机性变得更加严重。我认为这种随机行为是由于并行工作线程执行IO完成回调引起的。
使用的技术:F#套接字异步和SocketEventArgs。
我尝试的解决方案是:不是允许在服务器端从所有客户端接收,而是尝试轮询具有挂起数据的下一个可用客户端,然后可以确保正确的顺序,但其性能根本无法与以前的方法相比。