我正在尝试在Neo4J中加载一些数据。我已经设置好了一个名为
此外,数据来自具有数千行的CSV文件,因此我的查询需要是通用的,我无法为每个单独的“Person”节点设置属性。当我正在测试使用此子集创建电子邮件属性时,我的第一次尝试是这样的 -
这是结果 -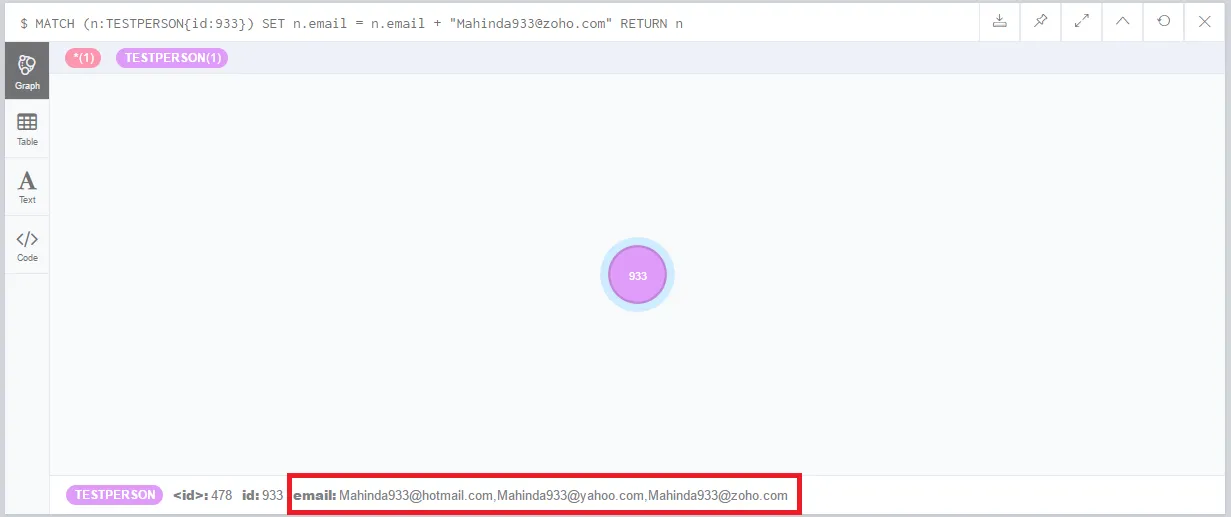 如您所见,
如您所见,
但问题在于,由于我的CSV文件有数千行,因此我需要一个通用查询来完成这项任务。
我考虑使用
Person的节点。现在,这个节点需要具有一个email属性,它应该是一个数组(或集合)。基本上,email属性需要具有多个值,如 -email: ["abc@xyz.com", "abc@foo.com"]
我在这里看到过类似的问题,但所有答案都表明要在创建节点本身的时候设置多个属性值。就像这篇答案中的查询一样 -
CREATE (e:Employee { name:"Sam",languages: ["C", "C#"]})
RETURN e
但我面临的问题是,Person节点已经创建,现在我需要设置其email属性。
这只是我需要加载的数据的一个小子集 -
Personid|email
933|Mahinda933@hotmail.com
933|Mahinda933@yahoo.com
933|Mahinda933@zoho.com
1129|Carmen1129@gmail.com
1129|Carmen1129@gmx.com
1129|Carmen1129@yahoo.com
4194|Ho.Chi4194@gmail.com
4194|Ho.Chi4194@gmx.com
此外,数据来自具有数千行的CSV文件,因此我的查询需要是通用的,我无法为每个单独的“Person”节点设置属性。当我正在测试使用此子集创建电子邮件属性时,我的第一次尝试是这样的 -
MATCH (n:TESTPERSON{id:933})
SET n.email = "Mahinda933@hotmail.com"
RETURN n
MATCH (n:TESTPERSON{id:933})
SET n.email = "Mahinda933@yahoo.com"
RETURN n
我想到了,这只是将email属性覆盖为最新查询中的值。
在查看这里和Cypher文档的答案后,我发现Neo4J允许您将数组/集合(相同类型的多个值)设置为属性值,然后我尝试了这个 -
// CREATE test node
CREATE (n:TESTPERSON{id:933})
RETURN n
// at this time, this node does not have any `email` property, so setup
// email as an array with one string value
MATCH (n:TESTPERSON{id:933})
SET n.email = ["Mahinda933@hotmail.com"]
RETURN n
// Now, using +=, I can append to the array of strings
MATCH (n:TESTPERSON{id:933})
SET n.email = n.email + "Mahinda933@yahoo.com"
RETURN n
// add a third value to array
MATCH (n:TESTPERSON{id:933})
SET n.email = n.email + "Mahinda933@zoho.com"
RETURN n
这是结果 -
如您所见,email属性现在具有多个值。但问题在于,由于我的CSV文件有数千行,因此我需要一个通用查询来完成这项任务。
我考虑使用
CASE语句,根据此处的文档尝试了以下内容:MATCH (n:TESTPERSON {id:933})
CASE
WHEN n.email IS NULL THEN SET n.email = [ "Mahinda933@hotmail.com"]
ELSE SET n.email = n.email + "Mahinda933@yahoo.com"
RETURN n
但是这只会抛出错误:mismatched input CASE expecting ;。
我希望能够使用这个查询作为我的CSV文件的通用方式,就像这样 -
LOAD CSV WITH HEADERS FROM 'FILEURL' AS line FIELDTERMINATOR `|`
MATCH (n:TESTPERSON {id:toInt(line.Personid)})
CASE
WHEN n.email IS NULL THEN SET n.email = [line.email]
ELSE SET n.email = n.email + line.email
但是,即使CASE错误被修复,我也不确定这是否有效。
我真的被卡住了,希望能得到任何帮助。谢谢。
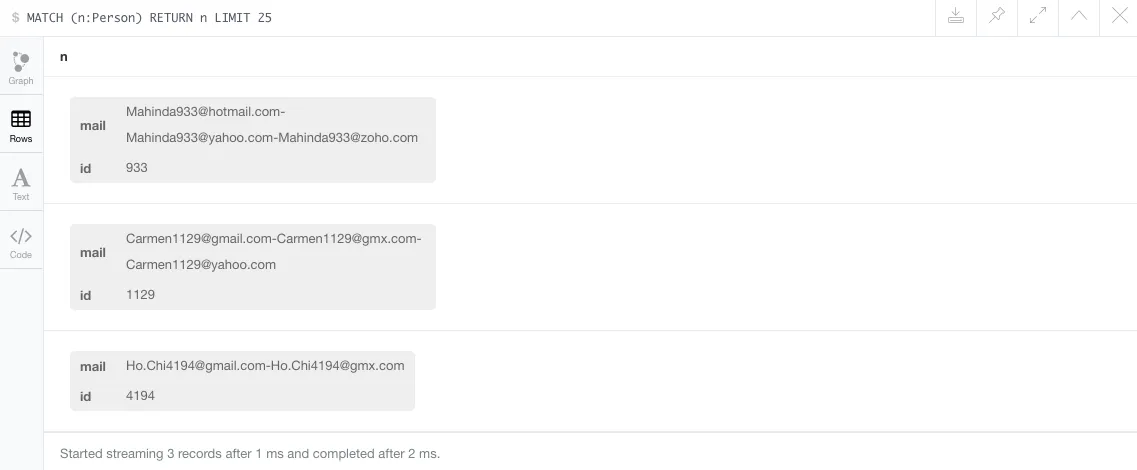
LOAD CSV WITH HEADERS FROM "fileURL" AS line FIELDTERMINATOR '|' MATCH (n:TESTPERSON {id: toInt(line.Personid)}) SET n.email = COALESCE(n.email, []) + line.email- Manish Giri