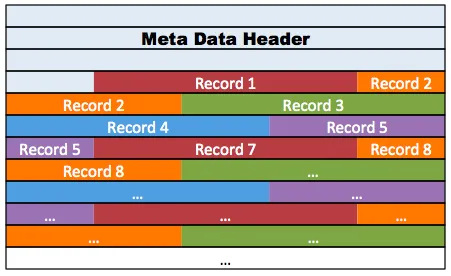
void computeRecord(void *taskInput)
{
struct TaskData *taskData = (TaskData *)(taskInput);
RecordData data;
// A huge long computation block to populate data
// (4-5 second run time)
long record_id = taskData->record_id;
char *buffer = taskData->start_buffer;
// mutex lock needed here ??
int n_bytes = sizeof(RecordData)
memcpy( (char *)(buffer+record_id*n_bytes), (char *)(&recordData) n_bytes);
// mutex unlock here ?
}
长篇设置。简短问题。在这种情况下,互斥锁是否必要?