我想知道写时复制是什么以及它的用途。这个术语在Sun JDK教程中被提到了多次。
9个回答
223
我原本想写自己的解释,但这篇维基百科文章已经总结得很好了。
以下是基本概念:
“Copy-on-write”(有时称为“COW”)是计算机编程中使用的一种优化策略。其核心思想是,如果多个调用者请求最初不可区分的资源,您可以将它们指向同一个资源的指针。此函数可以保持不变,直到调用者尝试修改其资源“副本”,此时将创建真正的私有副本,以防止更改对其他人可见。所有这些都对调用者透明。主要优点是,如果调用者从不进行任何修改,则永远不需要创建私有副本。
以下是常见COW应用程序之一:
COW概念也用于数据库服务器(如Microsoft SQL Server 2005)上即时快照的维护。当底层数据更新时,即时快照通过存储数据的预修改副本来保留数据库的静态视图。即时快照用于测试或时序相关报告,并不应用于替换备份。
- Andrew Hare
7
78
- Charlie Martin
5
2如果您进行更改,另一个人如何被通知您的新副本?难道他们不会看到错误的数据吗? - powder366
29不,他们不会看到错误的数据,因为只有在进行更改时才会实际创建一个副本。例如,您有一个名为
A的数据块。进程1、2、3、4都想要复制它并开始读取它。在“写时复制”系统中,尚未复制任何内容,但所有内容仍在读取A。现在,进程3想要更改其对A的副本,进程3将实际上创建A的一个副本并创建一个名为B的新数据块。进程1、2、4仍在读取A块,而进程3现在正在读取B块。 - Puddler1@Puddler如果在'A'中进行更改,会发生什么?所有进程将读取更新的信息还是旧的信息? - Developer
3@开发者:无论哪个进程正在修改
A,都应该创建一个新的副本。如果您问的是如果出现完全新的进程并更改 A,那么我的解释就不够详细了。这将是具体实现相关的,并需要了解您希望其余实现如何工作的知识,例如文件/数据锁定等。 - Puddler1@powder366 你的解释比被接受的答案更好! - RKA
11
- Shamik Majumdar
2
5“vfork 遵循写时复制(copy-on-write)的概念”这句话需要修改。事实上,
vfork 并没有使用 COW。实际上,如果子进程进行写操作,可能会导致不确定的行为和页面未被复制!事实上,可以说相反的情况有一定的真实性。当共享空间被修改时,COW 的行为类似于 vfork。 - Pavan Manjunath1完全同意Pavan的观点。
删除“vfork遵循写时复制的概念”的这行。现在,COW被用于fork作为一种优化方式,以便它像vfork一样运行,并且不会为子进程复制父进程的数据(如果我们只在子进程中调用exec*)。 - Shekhar Kumar
10
举个例子,Mercurial使用写时复制来使克隆本地仓库变得十分“便宜”。
原理与其他的例子相同,只是这里所说的是物理文件而不是内存中的对象。最初,克隆并不是副本,而是指向原始文件的硬链接。当你在克隆中更改文件时,会写入副本以表示新版本。
- harpo
7
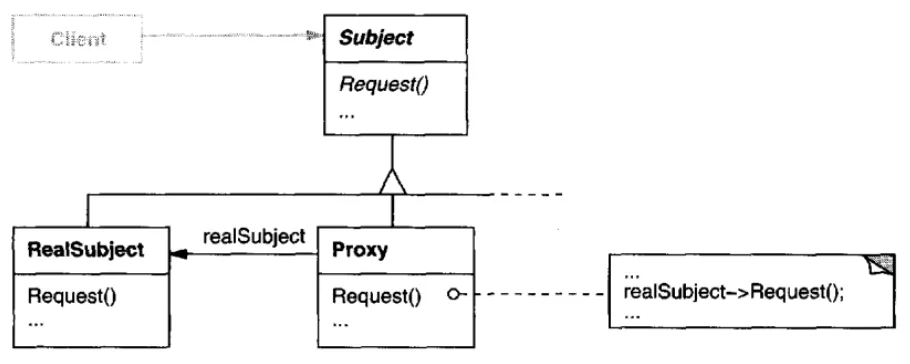
由Erich Gamma等人编写的设计模式:可复用面向对象软件的基础一书,清晰地描述了写时复制优化(章节“代理”中的“后果”部分):
代理模式在访问对象时引入了一层间接性。这种额外的间接性有很多用途,取决于代理的类型:1. 远程代理可以隐藏对象位于不同地址空间的事实。 2. 虚拟代理可以执行优化,例如按需创建对象。 3. 保护代理和智能引用允许在访问对象时执行附加的管理任务。
代理模式还可以隐藏客户端的另一种优化。它被称为“写时复制”,与按需创建相关。复制一个大而复杂的对象可能是一个昂贵的操作。如果副本从未被修改,则没有必要承担这个成本。通过使用代理来推迟复制过程,我们确保只有在对象被修改时才支付复制对象的代价。
为使写时复制起作用,主题必须被引用计数。复制代理只会增加此引用计数。只有当客户端请求修改主题的操作时,代理才会实际复制它。在这种情况下,代理还必须减少主题的引用计数。当引用计数降至零时,主题被删除。
写时复制可以显著降低复制重量级主题的成本。
以下是使用代理模式实现写时复制优化的Python代码。该设计模式的目的是提供一个替身对象来控制对另一个对象的访问。
代理模式的类图如下:
代理模式的对象图:

首先我们定义主题的接口:
import abc
class Subject(abc.ABC):
@abc.abstractmethod
def clone(self):
raise NotImplementedError
@abc.abstractmethod
def read(self):
raise NotImplementedError
@abc.abstractmethod
def write(self, data):
raise NotImplementedError
接下来,我们定义实现主题接口的真正主题:
import copy
class RealSubject(Subject):
def __init__(self, data):
self.data = data
def clone(self):
return copy.deepcopy(self)
def read(self):
return self.data
def write(self, data):
self.data = data
最后,我们定义代理实现主题接口并引用真实主题:
class Proxy(Subject):
def __init__(self, subject):
self.subject = subject
try:
self.subject.counter += 1
except AttributeError:
self.subject.counter = 1
def clone(self):
return Proxy(self.subject) # attribute sharing (shallow copy)
def read(self):
return self.subject.read()
def write(self, data):
if self.subject.counter > 1:
self.subject.counter -= 1
self.subject = self.subject.clone() # attribute copying (deep copy)
self.subject.counter = 1
self.subject.write(data)
客户端可以通过使用代理作为真实主题的替身来受益于写时复制优化:
if __name__ == '__main__':
x = Proxy(RealSubject('foo'))
x.write('bar')
y = x.clone() # the real subject is shared instead of being copied
print(x.read(), y.read()) # bar bar
assert x.subject is y.subject
x.write('baz') # the real subject is copied on write because it was shared
print(x.read(), y.read()) # baz bar
assert x.subject is not y.subject
- Maggyero
2
我找到了一篇关于 PHP 中 zval 的好文章,其中提到了 COW:
我发现this一篇很好的关于 PHP 中 zval 的文章,其中提到了 COW:
Copy On Write(缩写为“COW”)是一种旨在节省内存的技巧。 它更普遍地用于软件工程。 这意味着当您写入符号时,如果该符号已经指向 zval,则 PHP 将复制内存(或分配新的内存区域)。
- Amir Shabani
0
这是一个内存保护的概念。在这种情况下,编译器创建额外的副本来修改子级中的数据,而这些更新后的数据不会反映在父级数据中。
- Sushant
0
一个很好的例子是Git,它使用一种策略来存储blob。为什么要使用哈希?部分原因是因为这些更容易执行差异,但也因为这使得优化COW策略更简单。当您进行少量文件更改的新提交时,绝大多数对象和树都不会更改。因此,该提交将通过由哈希引用的各种指针引用已经存在的一堆对象,从而使存储整个历史所需的存储空间更小。
- Sam Keays
-1
它也被用于 Ruby 的“企业版”中,作为一种节省内存的巧妙方式。
- Chris
1
4我认为他并不是那个意思说 “used for”。 - spydon
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
clone()实现fork()时会使用它——子进程会复制父进程的内存,采用COW(写时复制)技术。 - Kerrek SB