如果我误解了,请纠正我,但是听起来你的解决方案的时间复杂度比O(nnkm)要高。
生成包含D中所有元素的所有可能划分列表需要O(nn)的时间。然后,对于每个划分中的每个子集(最多有n个子集),您需要验证是否存在与表匹配的项,这将需要每个子集的O(km)的时间。在n * n个可能的分区之后(实际上不是n * n,而是n的贝尔数),匹配每个最多包含n个集合的复杂度为O(nnnmk)。
话虽如此,我认为可以通过尝试构建一棵树来更快地完成它。
从D的开头开始,您可以尝试匹配表中的所有字符串。表中的每个字符串表示一个分支,如果表字符串与D的第一个位置不匹配,则该分支终止。如果匹配,则该过程在刚刚匹配的表字符串的末尾重新开始。
使用此方法的诀窍是,您只需要保留产生唯一长度的匹配序列。以广度优先的方式重复此过程意味着,如果已经发现了达到特定长度的一组表字符串,则再次达到该长度的任何表字符串集都保证包含来自表的相同数量或更多的字符串,但仍匹配D的相同子串。例如,表字符串{abab,ab}将都生成长度为4的字符串“abab”,但其中一个将在第一次迭代时匹配,而另一个将在第二次迭代时匹配。在此示例中,包含'ab'+'ab'的编码始终比包含'abab'的编码差,因此我们丢弃了'ab'+'ab'的编码。可以使用简单的O(1)查找表来检查这一点,并且任何已经看到的长度也可以终止其分支。因此,最多可以发现n个唯一长度,每个长度只能发现一次,这意味着最多可能有n个分支。
仍然必须检查表中的字符串,这仍然是O(mk)。加入分支后,
我相信这会产生O(nmk)的复杂度,因为最多创建n个分支。
例如,在字符串'aaaaaa'上的表{a,aa}将每个迭代包含2个分支,共3次迭代。每个分支需要O(mk)的时间进行检查,因此此示例的时间复杂度为O(nmk)。
编辑:由于对我的提议实现存在一些怀疑,我已经在C中实现了它并进行了一些分析。
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
const char* alphabet = "abcdef";
const int alphabetLen = strlen(alphabet);
void printTable(char** table, int k){
printf("Table: {%s", table[0]);
for(int i=1; i<k; i++){
printf(", %s", table[i]);
}
printf("}\n");
}
char** generateTable(int k, int m){
char** table = (char**)malloc(sizeof(char*)*k);
for(int i=0; i<k; i++){
int tableStringLen = (rand() % (m-1)) + 1;
table[i] = (char*)malloc(tableStringLen+1);
for(int j=0; j<tableStringLen; j++){
table[i][j] = alphabet[rand() % alphabetLen];
}
table[i][tableStringLen] = 0;
}
return table;
}
char* generateString(char** table, int k, int m){
int minLength = rand()%200 + m*2;
char* string = (char*)malloc(minLength + m);
int j = 0;
for(int i=0; j<minLength; i++){
int tableStringIndex = rand() % k;
strcpy(string+j, table[tableStringIndex]);
j += strlen(table[tableStringIndex]);
}
string[j] = 0;
return string;
}
void printSolution(char* string, int* branchLengths, int n){
if(!n){ return; }
printSolution(string, branchLengths, branchLengths[n]);
printf("%.*s ", n-branchLengths[n], string+branchLengths[n]);
}
int* solve(char* string, char** table, int n, int m, int k, int* comparisons){
int* currentBranchEnds = (int*)calloc(sizeof(int), n);
int currentBranchCount = 1;
int* newBranchEnds = (int*)calloc(sizeof(int), n);
int newBranchCount = 0;
int* branchLengths = (int*)calloc(sizeof(int), (n+1));
int* tableStringLengths = (int*)malloc(sizeof(int) * k);
for(int i=0; i<k; i++){ tableStringLengths[i] = strlen(table[i]); }
*comparisons = 0;
while(!branchLengths[n]){
for(int i=0; i<currentBranchCount; i++){
for(int j=0; j<k; j++){
int newBranchEnd = currentBranchEnds[i] + tableStringLengths[j];
*comparisons += 1;
if(newBranchEnd > n || branchLengths[newBranchEnd]){ continue; }
char match = 1;
for(int l=0; table[j][l]; l++){
*comparisons += 1;
if(string[currentBranchEnds[i] + l] != table[j][l]){
match = 0;
break;
}
}
*comparisons += 1;
if(match){
branchLengths[newBranchEnd] = currentBranchEnds[i];
newBranchEnds[newBranchCount] = newBranchEnd;
newBranchCount += 1;
}
}
}
int* tmp = currentBranchEnds;
currentBranchEnds = newBranchEnds;
newBranchEnds = tmp;
currentBranchCount = newBranchCount;
newBranchCount = 0;
}
free(currentBranchEnds);
free(newBranchEnds);
free(tableStringLengths);
return branchLengths;
}
int main(){
int k = rand() % 30 + 2;
int m = rand() % 15 + 2;
char** table = generateTable(k, m);
printTable(table, k);
char* string = generateString(table, k, m);
int n = strlen(string);
printf("String: %s\n", string);
int comparisons;
int* solution = solve(string, table, n, m, k, &comparisons);
printf("Solution: ");
printSolution(string, solution, n);
printf("\n");
printf("Comparisons: %d\n", comparisons);
for(int i=0; i<k; i++){ free(table[i]); }
free(table);
free(solution);
free(string);
}
通过对 n、m 和 k 的随机生成的值运行算法500000次,生成了该分析结果。在代码中,每遇到一个 if 语句就会增加“比较”的数量,这个数量会随着变量n、m和k的值而改变, 平均每个 n、m 和 k 值的比较次数被绘制成图表。
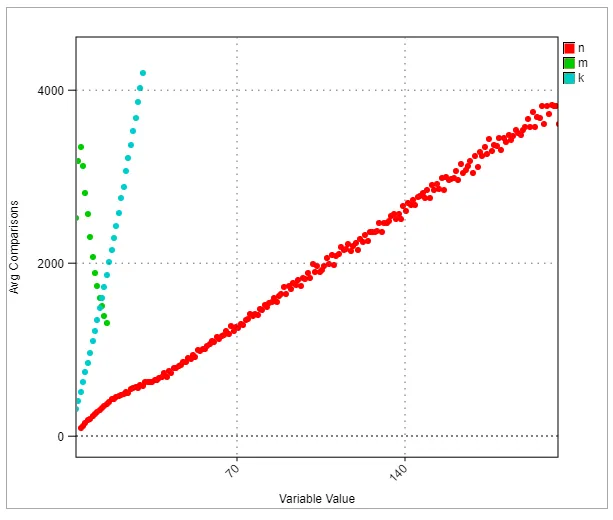
很明显,比较次数(计算出来的)与 n、m 和 k 的大小之间存在线性关系。这表明复杂度为 O(nmk)。